10 août 2017
Il y a quelques années, quand quelqu'un voulait réaliser une extraction OSM des arrêts de bus, il se retrouvait confronté à un problème :
- pour certains, un arrêt de bus est un lieu sur le bord de la route, où des voyageurs attendent leur bus
- pour d'autres, c'est un endroit sur la voirie, où un bus s'arrête
La nuance peut sembler légère, mais cela peut jouer sur la volumétrie : lorsqu'on a deux abribus en face, on peut se retrouver avec deux arrêts selon la première définition, mais un unique arrêt avec la seconde...
Pour résoudre ce souci, la communauté OSM a planché sur une nouvelle modélisation des arrêts (entre autres), qui a été adoptée par vote en 2011.
Deux nouveaux attributs viennent compléter le modèle : l'un désigne l'endroit sur la chaussée où le bus s'arrête (public_transport = stop_position), et l'autre désigne l'endroit où les voyageurs attendent (public_transport = platform).
Un problème, une solution, KISS !
Vraiment ?
Admettons, pour les besoins de l'exercice, que je sois intéressée par les arrêts de bus, au sens "les endroits où les voyageurs attendent leur bus".
Facile donc, si je veux extraire tous les arrêts de France, je n'ai qu'à filtrer mes données OSM sur le tag public_transport = platform.
Voici les résultats de mon extraction (sur des données du 4 aout 2017) : en France métropolitaine, on a d'après OSM, 45 408 arrêts où attendent des voyageurs.
Là, si le résultat ne vous choque pas, croyez-moi sur parole : ce n'est pas crédible.
Rien qu'en Île-de-France, on a déjà environ 40 000 arrêts de transport en commun, donc, même si la base OSM n'est pas exhaustive, ce n'est pas vraiment le bon ordre de grandeur.
Ok, par curiosité, si j'utilise le tag historique higwhay = bus_stop, qu'est-ce que ça donne ?
123 956 arrêts. Déjà plus crédible.
Mais souvenez-vous, pour certains, un arrêt de bus désigne un endroit sur la route, et moi je veux les abribus et les poteaux où les gens attendent. Essayons de combiner : si je prends les highway = bus_stop qui ne sont pas des public_transport = stop_position : 98 173 arrêts.
Bon, si je regarde dans le détail, je trouve que la plupart de ces arrêts n'ont pas le tag public_transport de renseigné du tout. Difficile de savoir quelle proportion de ceux là sont dont des stop_position qui ne m'intéressent pas.
Au final, combien ai-je d'arrêts ? 45 mille, 98 mille ou 124 mille ?
Bref, six ans après l'adoption du nouveau schéma, extraire les arrêts de bus est une opération qui reste hasardeuse...
Exigeons plus ! Et si, en tant que contributeur OSM, on appliquait le schéma et qu'on ajoutait scrupuleusement stop_position ou platform sur tous les higwhay=bus_stop ?
Une analyse Osmose est déjà disponible pour identifier les arrêts à compléter : c'est par ici que ça se passe, et c'est très facile à corriger !
Même si cela ne suffira pas, ce sera déjà la première marche vers plus de réutilisabilité des données OSM \o/
Et en cadeau, si vous être arrivés jusque là dans cet article passionnant, voici des représentations cartographiques de la répartition de ces différentes combinaisons d'attributs.
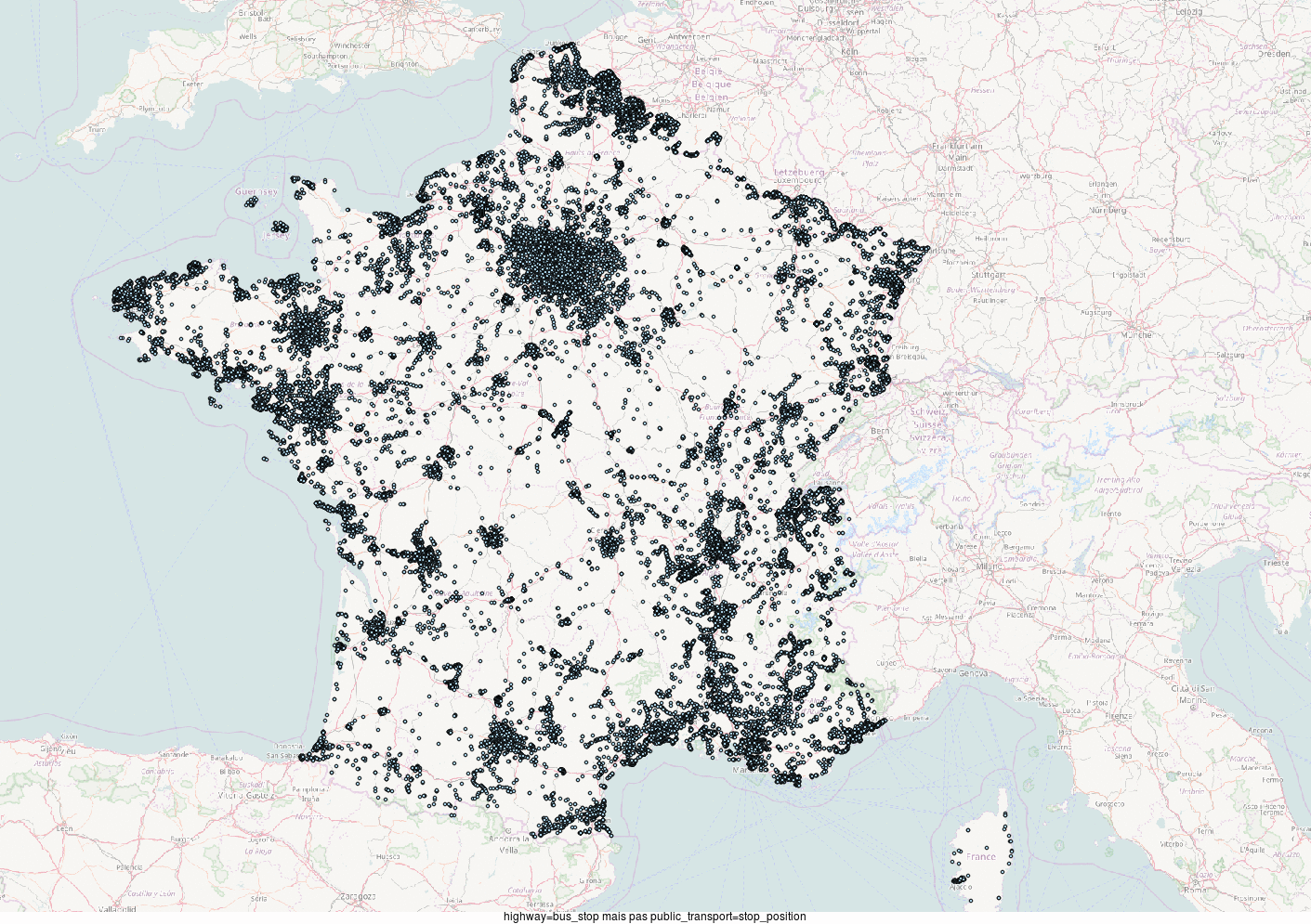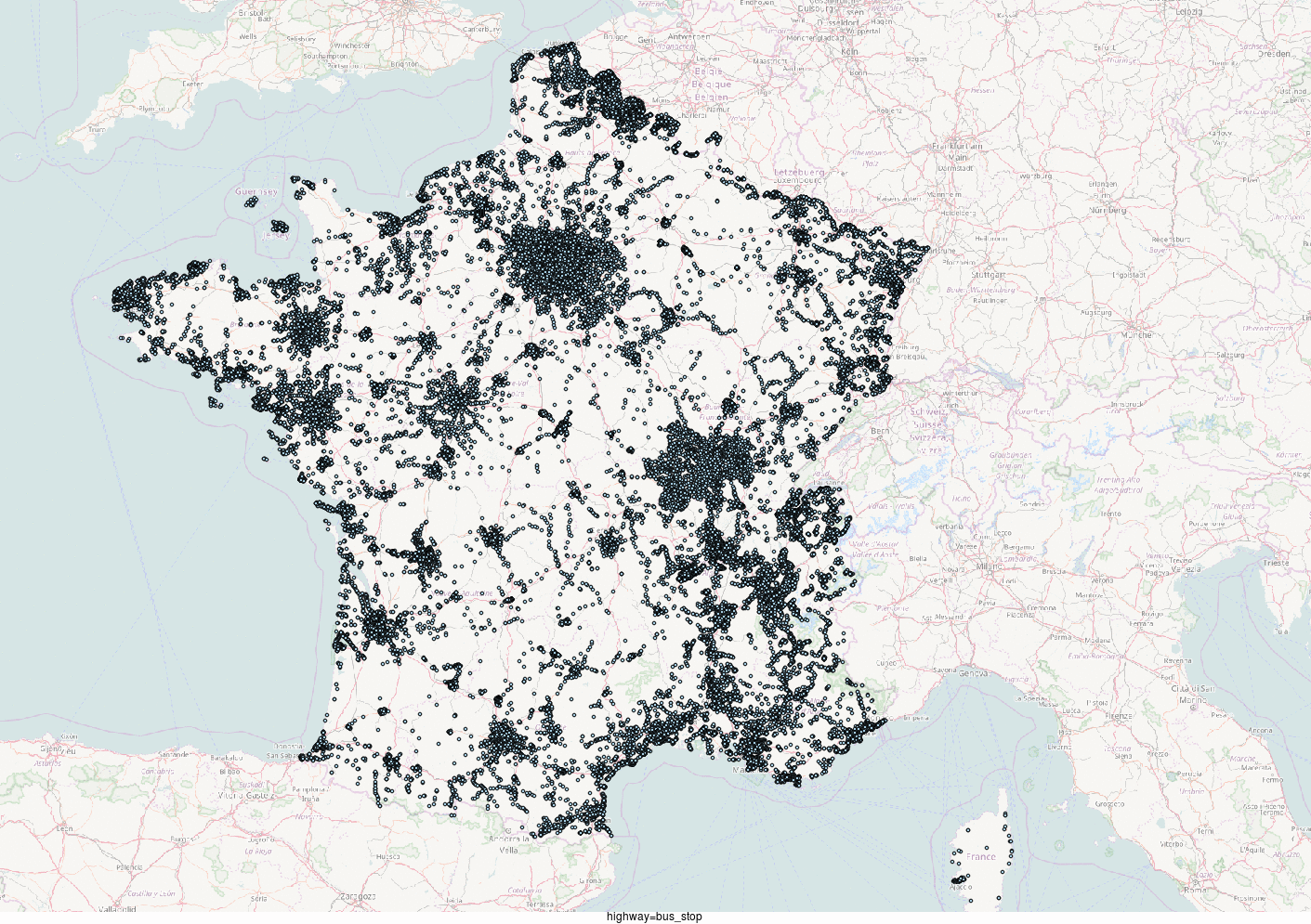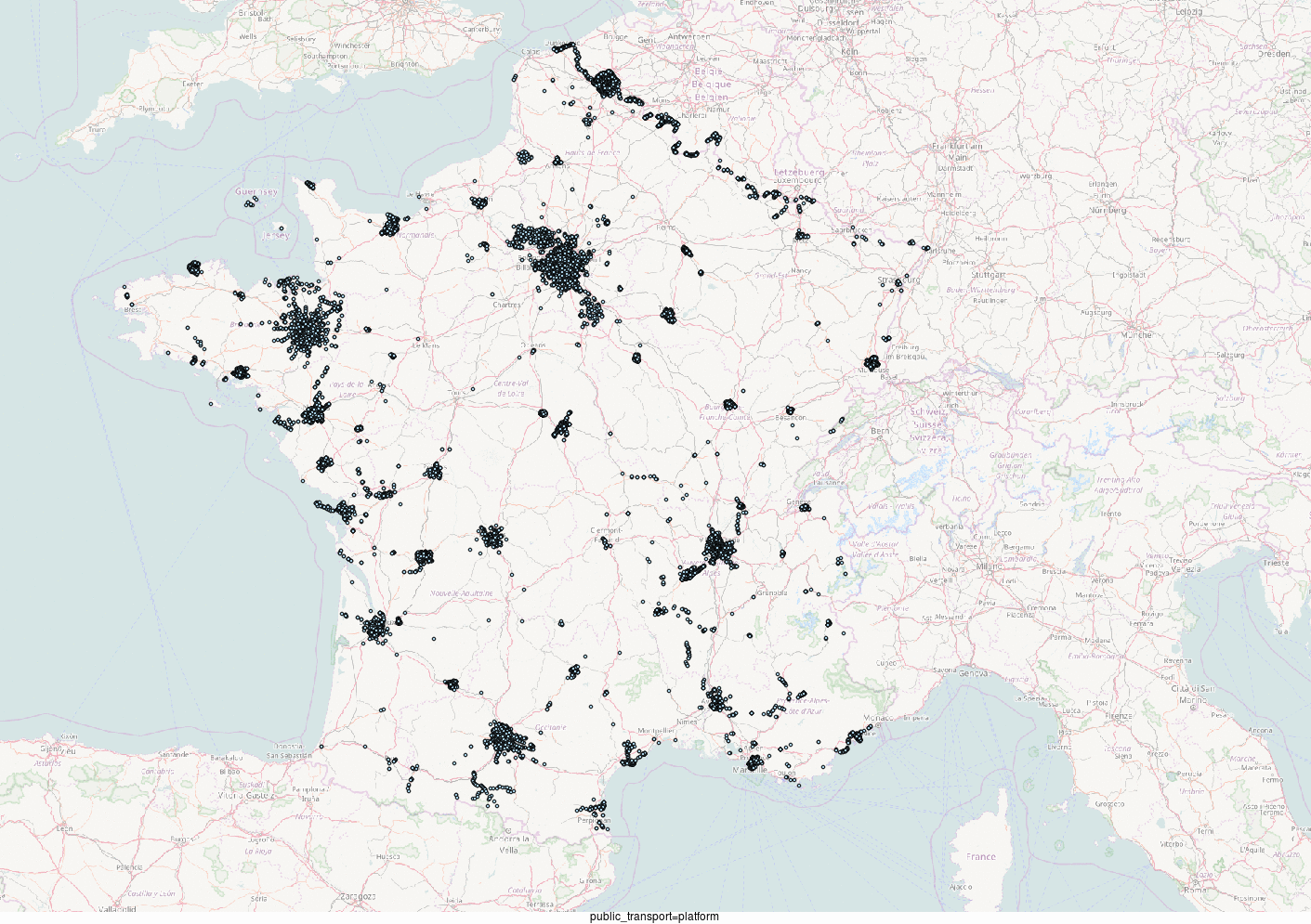
NB : Cet article comprend des approximations et simplifications pédagogiques.
D'ailleurs, si vous les avez remarquées, n'hésitez pas à venir prolonger la discussion sur la liste de diffusion transport de la communauté OSM France, par ici ;)
03 août 2017
Le génial service Overpass-turbo permet depuis quelques temps de sauvegarder ses requêtes favorites via son compte OSM.
Voici la liste des requêtes que je me suis enregistrées, sur la thématique des bus :
Arrêts à proximité
Liste des arrêts à 500 mètres d'une position (ici 48.86343,2.40997) :
[out:csv(::"id", name, public_transport, "ref:FR:STIF", ::"user")];
//[out:json];
node
(around:500,48.86343,2.40997)
["highway"="bus_stop"];
out;
Arrêts à proximité, avec les parcours desservis
Liste des arrêts à 500 mètres d'une position, avec le détail des parcours qui passent à ces arrêts :
[out:json];
(
node
(around:500,48.86343,2.40997)
["highway"="bus_stop"];
)->.a;
rel(bn);
out body;
.a out body;
Arrêts d'une zone, avec les parcours desservis
Liste des arrêts d'une zone géographique, avec comme précédemment, le détail des parcours qui passent à ces arrêts :
[out:json];
(
node
["highway"="bus_stop"]
({{bbox}})
)->.a;
rel(bn)["route"="bus"];
out center;
.a out body;
Arrêts d'un parcours
Liste de tous les arrêts d'un parcours en particulier (défini par son id, ici 1083331)
[out:csv(::"id", name, public_transport, "ref:FR:STIF", ::"user")];
relation(1083331);node(r:"platform");out meta;
Si la ligne n'est pas en schéma v2, alors remplacer platform par stop :
[out:csv(::"id", name, public_transport, "ref:FR:STIF", ::"user")];
relation(1257174);node(r:"stop");out meta;
Arrêts non desservis
Liste des arrêts qui ne sont desservis par aucune ligne de bus.
//[out:csv(::"id", name, public_transport)];
[out:json];
node({{bbox}})["highway"="bus_stop"]->.all;relation(bn.all)["route"="bus"];node(r);
( .all; - ._; );out skel;
Arrêts sans nom
Liste des arrêts de bus sans nom d'une zone géographique :
[out:csv(::"id", public_transport, "ref:FR:STIF", ::"user")];
(
node
["highway"="bus_stop"][!"name"]
({{bbox}})
);
out body;
Nombre d'arrêts sans nom d'un parcours
Liste des arrêts de bus d'un parcours qui n'ont pas de nom renseigné :
[out:csv(total)];
//[out:json];
relation(1083331);node(r:"platform")[!"name"];out count;
Comme précédemment, si la ligne respecte le schéma v1 et non le v2, alors il faudra remplacer platform par stop.
Parcours d'une zone
Liste des parcours de bus dans une zone géographique :
[out:csv(::"id", name, network, operator, ::"user")];
(
relation["route"="bus"]({{bbox}});
);
out meta;
Parcours orphelins
Liste des parcours de bus qui n'ont pas de ligne de bus associée
[out:csv(::"id", name, network, operator, ::"user")];
rel({{bbox}})["route"="bus"]->.all;
rel["route_master"="bus"](br.all);
rel["route"="bus"](r);
( .all; - ._; );
out meta;
Avec ça, vous avez tout ce qu'il faut pour prendre soin des bus dans OSM ;)
28 mai 2017
Aujourd'hui, je vous propose quelques rappels théoriques sur comment bien cartographier les bus dans OSM.
EDIT : cet article est un peu vieillissant mais est souvent partagé aux débutants qui se lancent vaillamment à l'assaut de la cartographie des bus. Il a donc été réécrit et légèrement modernisé : Bien cartographier les bus dans OSM.
NB : Je prends pour référence le modèle dit "Public Transport v2", approuvé par la communauté OSM en 2010. À noter qu'il n'y a pas eu de mise à niveau globale vers ce modèle et donc que le modèle historique, plus simple mais moins précis, continue d'exister et est souvent le seul reconnu par les outils utilisant les données OSM.
Pour commencer, on a l'arrêt de bus.

Dans le modèle historique, pour cartographier cet arrêt de bus, on se contentait de mettre un tag highway = bus_stop, en général au niveau du trottoir.
Mais ça, c'était avant ! Maintenant, on crée deux objets dans OSM :
Tout d'abord, pour désigner l'endroit où le voyageur attend le bus (ici, l'abribus), on crée un nœud, avec les tags public_transport = platform.
Pour bien préciser le mode (car ce tag s'applique aussi pour les arrêts de tram ou de train), et pour la rétro-compatibilité avec l'ancien modèle (notamment sur les outils de rendu), on ajoute également highway = bus_stop.
Puis, on peut créer un deuxième nœud, qui représente l'endroit sur la chaussée où le bus s'arrête. À noter que le nœud doit faire partie du chemin décrivant la route et non pas être posé dessus.
Sur ce nœud, on ajoute les tags public_transport = stop_position et bus=yes
Une fois qu'on a fait ça, on peut ajouter les infos contextuelles propres à cet arrêt, comme son nom (name = ...), s'il y a un abri (shelter =yes/no), un banc (bench = yes/no), une bande podotactile, etc
En général, on ajoutera tout ça uniquement sur l'objet platform (même s'il est courant de répéter le nom aussi sur le stop_position).

Une fois qu'on a bien cartographié notre arrêt, il nous faut indiquer quels bus s'y arrêtent.
Les lignes de bus sont représentées dans OSM par des relations, c'est-à-dire des objets qui sont des regroupements d'autres objets.
Une ligne de bus dans OSM sera une relation de type = route_master.
On lui ajoutera les autres tags suivants :
- route_master = bus pour indiquer son mode
- ref = un nombre, pour indiquer le numéro de la ligne
- operator = ..., pour renseigner l'entreprise qui fait rouler ces bus
- network = ..., pour indiquer le nom du réseau
- name = ..., pour indiquer le nom de la ligne
Dans cette relation ligne de bus, on mettra les objets OSM qui représentent les variantes de tracés de la ligne, ses parcours.
En général, on aura au moins le parcours de la ligne en sens aller et le parcours de la ligne en sens retour. On trouvera aussi parfois le parcours spécial du matin qui s'arrête devant l'école, ou le parcours spécial du jeudi qui passe dans une autre rue à cause du marché.
Les parcours (variantes de lignes ou trajets) sont aussi des relations, de type = route.
On leur ajoute les tags suivants :
- route = bus pour indiquer le mode
- ref = un nombre, pour rappeler le numéro de la ligne
- operator = ..., pour rappeler l'entreprise qui fait rouler ces bus
- network = ..., pour rappeler le nom du réseau
- name = ..., pour indiquer le nom du parcours
- from = ..., pour indiquer le point de départ du parcours
- to = ..., pour indiquer la destination du parcours
- public_transport:version = 2, pour indiquer qu'on utilise le "nouveau" modèle et non le modèle historique
Et dans cette relation parcours, on ajoute :
- tous les chemins que prend le bus
- nos fameux arrêts, platform et stop_position, dans l'ordre où ils sont desservis.

En particulier, on ajoutera les platform avec le rôle ... platform, et les stop_position avec le rôle ... stop (ben oui, vous pensiez quand même pas que ça serait si simple !).
Et on le fera bien sûr pour toutes les lignes (ou plus précisément variantes de lignes) qui s'arrêtent à cet arrêt.
Si vous avez bien suivi, on a donc des nœuds (platform et stop_position), qu'on met dans les relations (type = route), qu'on met elles-mêmes dans des relations (type = route_master)
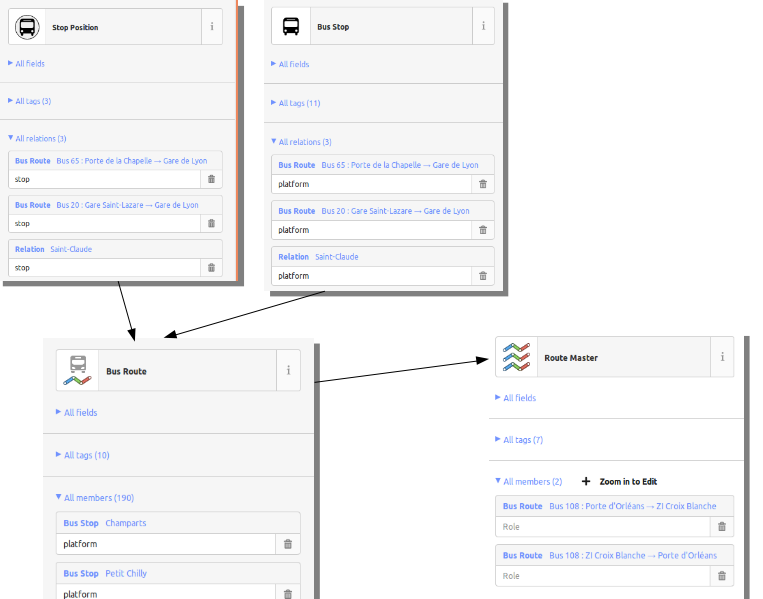
À noter que dans le modèle historique, les relations parcours (type = route) contenaient uniquement les arrêts (highway = bus_stop) avec le rôle stop. Avec le nouveau modèle, les objets qui ont le tag highway=bus_stop ont en général plutôt le rôle platform.
Pour bien savoir ce que représente un objet qui a le rôle stop, on ajoute public_transport:version = 1 sur les relations parcours (type = route) qui ont été cartographiées suivant le modèle historique et n'ont pas encore été mises à niveau.
Vous suivez toujours ? Parce que ce n'est pas fini !
Pour rassembler tous les arrêts en correspondance, on utilisera encore une autre relation, avec les tags type = public_transport et public_transport = stop_area.
De la même manière, les platform auront le rôle platform, et les stop_position le rôle stop.
Ces relations sont encore très peu répandues dans OSM ; pour les bus on les retrouve surtout dans les grandes gares routières.
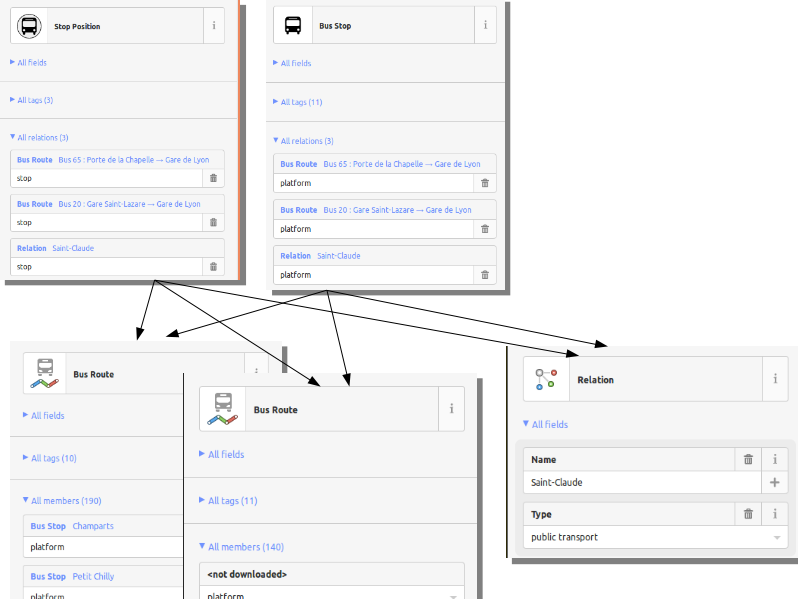
Une fois que vous avez ajouté vos platform et stop_position dans tous les parcours (type = route et route = bus) et dans sa zone d'arrêt (type = public_transport et public_transport = stop_area), vous avez fini !
Félicitations, vous pouvez maintenant vous attaquer à l'arrêt de bus qui est de l'autre côté de la rue ;)
Le mot de la fin :
Vous trouvez que tout ceci est bien compliqué pour pas grand chose, et qu'on devrait pouvoir faire ça de manière transparente dans une appli, directement quand on est sur le terrain ?
Vous avez raison : soutenez le projet Jungle Bus pour rendre tout ceci possible !
Vous pestez parce que je n'ai pas parlé des rôles exit_only et entry_only, ni du fait qu'il fallait parfois couper les chemins ? Rejoignez le projet Jungle Bus, les bussophiles sont y sont accueillis à bras ouverts ;)
03 mai 2017
Il y a un petit plus d'un mois, je vous proposais une méthode étonnamment simple pour améliorer un peu la qualité des arrêts de bus dans OSM au quotidien, en ajoutant les noms lorsqu'ils manquaient.
C'était trop facile, vous en voulez encore ?!
Ça tombe bien, on l'a vu dans mon précédent article, il y a encore plein de choses à faire en Île-de-France sur le sujet :)
En attendant que le projet Jungle Bus ne nous permette de changer le monde en mettant toujours plus de réseaux de transport sur la carte, voici ce que vous pouvez déjà faire en Île-de-France :
Un peu plus difficile que mon précédent challenge, je vous propose aujourd'hui d'ajouter dans OSM les lignes qui passent aux arrêts de bus.
Voici une liste d'arrêts où aucune information n'est disponible sur les lignes qui s'arrêtent.
Si vous la téléchargez sur votre mobile, vous pouvez visualiser tout cela dans MAPS.ME (en rose à présent)
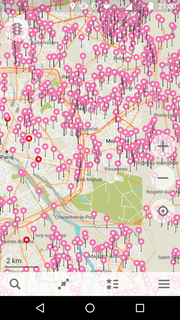 Comme vous pouvez le voir, il y a du boulot.
Comme vous pouvez le voir, il y a du boulot.
Puis, quand on passe devant l'arrêt, on peut cliquer sur le signet, puis sur "AJOUTER DES LIGNES".
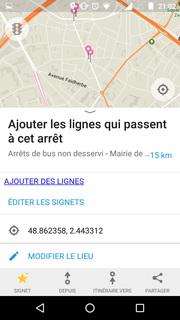
On ne peut malheureusement pas visualiser ou modifier les lignes qui desservent les arrêts dans MAPS.ME.
On est en fait redirigé vers MicrocOSM, une autre webapp de mon cru ;)
NB : à la première utilisation, il faudra revenir à l'accueil de MicrocOSM pour se connecter à OSM, refermer la page, et refaire la manip depuis MAPS.ME
On peut alors cliquer sur Modifier.
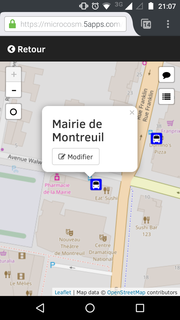
Là, dans le champ TODO, on peut rechercher une ligne et l'ajouter.
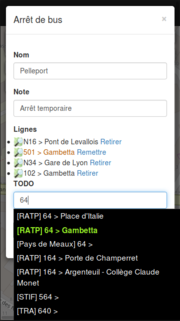
Ne pas oublier de cliquer sur Enregistrer quand on a ajouté toutes les lignes ;)
Si vous ne trouvez pas votre ligne dans la liste, c'est probablement que la ligne n'existe pas encore dans OSM, ou qu'elle est en piteux état.
Mais ça, ça sera peut-être l'objet d'un prochain challenge et d'un prochain article de blog !
Quoiqu'il en soit, n'hésitez pas à me contacter sur OSM si vous rencontrez des soucis.
Et si c'est encore trop facile pour vous, voici un autre challenge :
Tous ces arrêts de bus ont un tag FIXME.
Votre mission, si vous l'acceptez, est d'aller sur le terrain voir de quoi il est question, et de faire le nécessaire pour pouvoir retirer ce tag !
Quelques volumétries à date :
Rendez-vous dans quelques semaines pour faire le bilan.
EDIT : un grand merci à prhod et Manu1400 pour leurs contributions opensource pour améliorer ces outils suite à la première publication de cet article ;)
EDIT octobre 2018 : mise à jour de liens (les fichiers kml sont maintenant hébergés sur github).
26 avril 2017
Ceci est, à peu de chose près, la retranscription de la présentation que j'ai donnée hier, à la soirée de lancement du projet Jungle Bus, qui vise à révolutionner la production des plans de transport, en s'appuyant sur le crowdsourcing et OpenStreetMap.
La plupart des villes du monde n'ont pas de plan de transport.
Mais qu'en est-il de la votre ? Qu'en est-il de la mienne ?
J'ai fait l'expérience, j'ai cherché un plan de transport de là où j'habite actuellement.
J'ai commencé par regarder du côté du STIF ; voici ce qu'ils proposent :
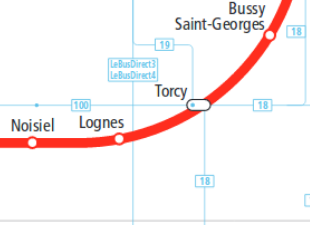 source : STIF
source : STIF
On retrouve quelques lignes : la ligne 100, les deux lignes 18, la ligne 19.
Mais c'est un plan schématique qui n'affiche que les lignes structurantes : des choix de représentation ont dû être faits, toutes les lignes ne sont pas présentes, et on ne sait pas vraiment où elles passent et si on peut les prendre.
On retrouve également les lignes Bus Direct qui, à ma connaissance, ne s'arrêtent pas, voire ne passent pas du tout ici.
Essayons en un autre ; voici celui de la RATP :
 source : RATP
source : RATP
Celui-ci est plus précis, et prend en compte la réelle géographie de la ville : on voit des cours d'eau, des forêts, quelques rues.
En terme de transport, on a maintenant des tracés, et des indications des arrêts. On retrouve les lignes RATP, la 211, la 220, la 321, la 421. On retrouve aussi la ligne 100 déjà présente sur le plan schématique du STIF.
Bon ce n'est pas parfait, la ligne 100 n'est pas rouge mais bleue en réalité.
Et les deux lignes 18 et la ligne 19 ?
Voyons celui du réseau Noctilien :
 source : Noctilien, STIF
source : Noctilien, STIF
Là encore c'est un plan qui tient compte de la géographie, mais sans surprise, seules les lignes du réseau Noctilien sont indiquées.
Bon point tout de même, on a, en supplément de leur positions, les noms des arrêts.
J'y vois tout de même des positions qui me semble légèrement fausses.
Enfin, un petit dernier, proposé par le réseau Pep's
 source : Transdev idf
source : Transdev idf
Celui-ci est vraiment pas mal !
On a à présent une liste exhaustive de toutes les lignes de transport, et pas uniquement celles du réseau Pep's. On retrouve bien les lignes structurantes (la 100, les deux 18 et la 19), les lignes RATP citées plus tôt, les lignes Noctilien citées plus tôt, les lignes Pep's évidemment, et les quelques autres.
Mais faisons l'exercice, que donnerait un plan réalisé à partir des données OpenStreetMap ?
Voici le fond transport actuel officiel du projet OpenStreetMap
 source : OSM fond Transport
source : OSM fond Transport
On ne va pas se mentir, ce n'est pas génial.
On a des tracés, on a des numéros de lignes, on a des arrêts et des noms d'arrêts, mais c'est pas bien clair qui appartient à quoi.
Pour les couleurs de lignes, on repassera : elles ont beau être renseignées, elles ne sont pas affichées. Et quant à savoir si toutes les lignes citées plus haut y sont, c'est loin d'être évident.
C'est d'ailleurs un des objectifs du projet Jungle Bus : fournir un rendu cartographique des réseaux de transports lisible et exploitable.
Mais en attendant, essayons au moins de connaitre l'exactitude de cette carte.
Pour cette zone géographique, je la connais, j'en ai cartographié moi-même une partie significative.
Mais à l'échelle de l'Île-de-France, quelle exactitude aurait un plan de transport fait à partir d'OSM ?
Voyons déjà la quantité d'information disponible :
Si je compte les arrêts de transport de la région, j'en ai plus de 20 000 !
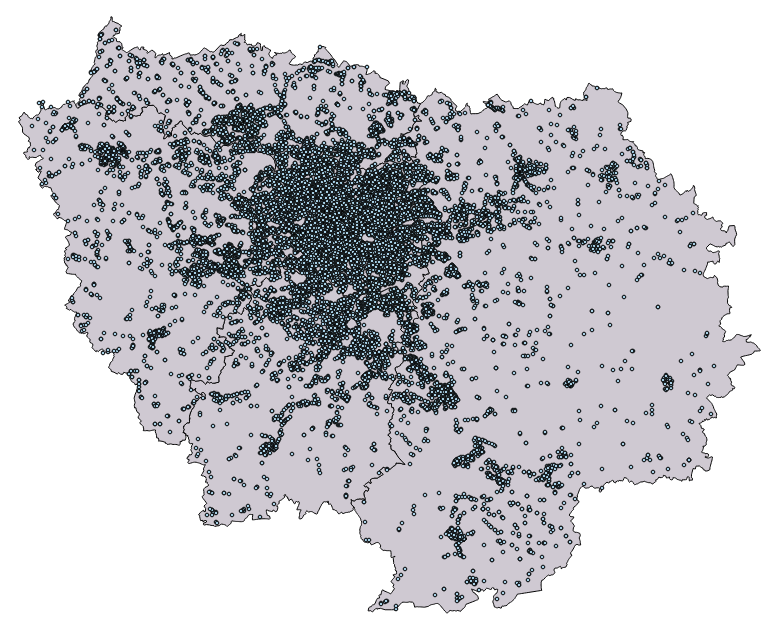 source : <3 les contributeurs OSM (arrêts et contours)
source : <3 les contributeurs OSM (arrêts et contours)
Ok, ça fait beaucoup, mais est-ce qu'ils y sont tous ?
Pour le savoir, c'est plus simple qu'il n'y parait !
En effet, le STIF, qui organise et finance les transports publie un certain nombre d'informations sur son portail opendata, j'en parlais déjà dans un précédent article.
La liste et la position de tous les arrêts d'Île-de-France sont donc facilement récupérables et utilisables en comparaison.
Voici la différence entre OSM et les données STIF, que nous considérerons ici comme la représentation la plus juste de la réalité en terme de quantités d'arrêts:
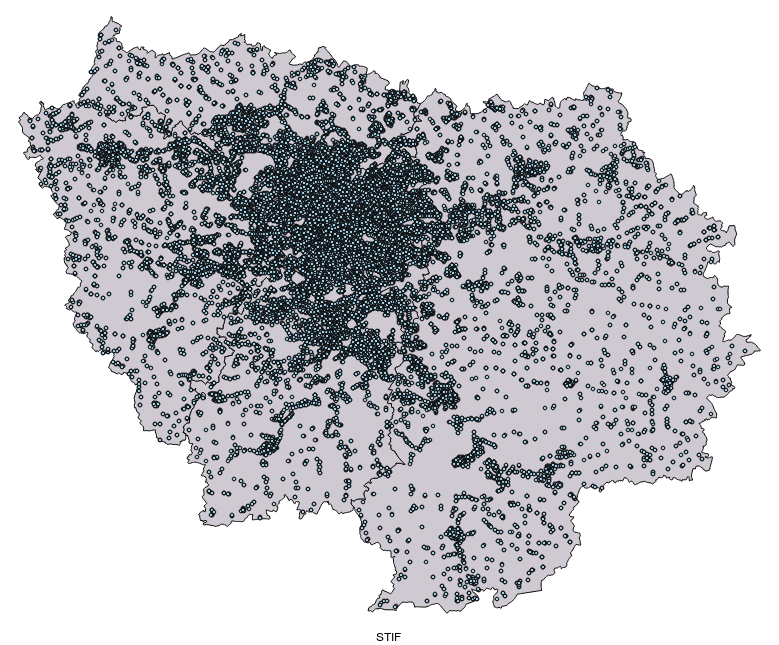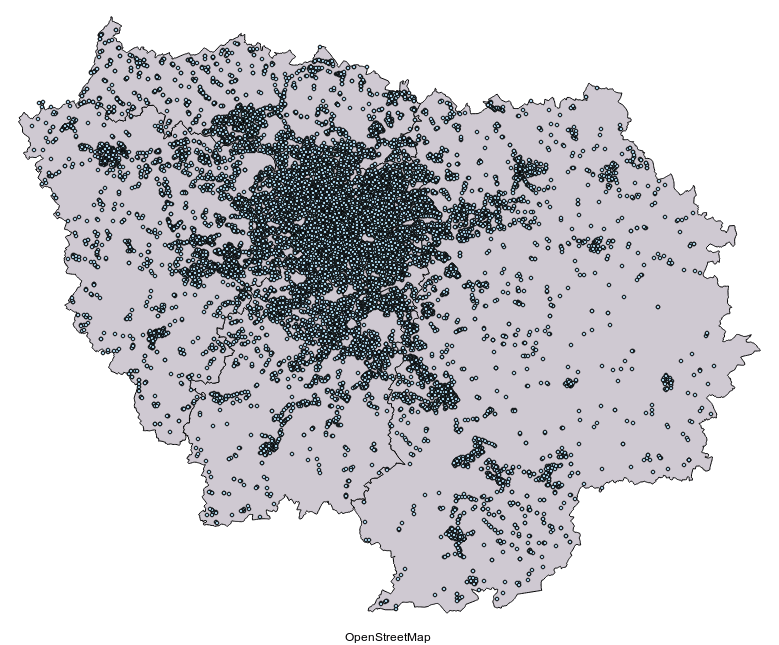 source : données OSM (c) contributeurs OSM / données STIF - portail opendata
source : données OSM (c) contributeurs OSM / données STIF - portail opendata
Il en manque. Beaucoup. Surtout sur les bords.
En réalité, le tableau est même plutôt sombre.
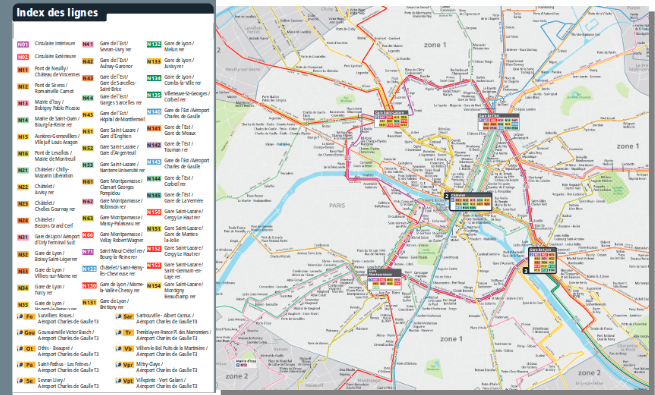
Si on voulait faire un plan de transport de la région Île-de-France, il ressemblerait à ça : d'un côté une carte avec les lignes tracées, et de l'autre une liste des lignes pour pouvoir les retrouver facilement.
Si on réalisait aujourd'hui ce plan avec OSM, on aurait plutôt cela :
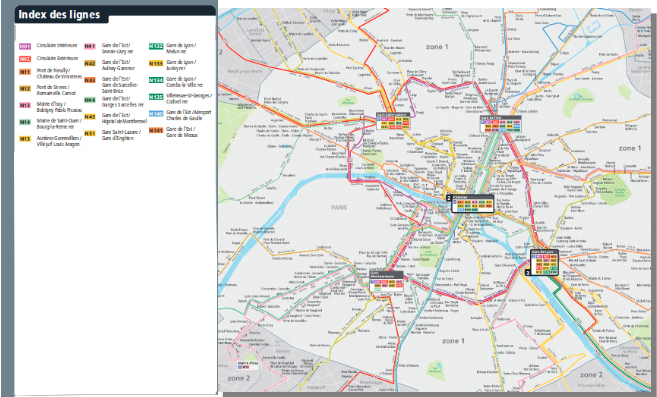
Oui, plus de la moitié des lignes est aujourd'hui manquante dans OSM !
Et tout cela donne une représentation faussée et inégale du territoire. Car les lignes cartographiées sont probablement les plus empruntées et celles où il y a le plus de contributeurs.
La répartition des arrêts le montrait déjà, mais en voici un exemple encore plus frappant : voici le nombre de lignes par réseau, dans OSM, et dans les données du STIF :
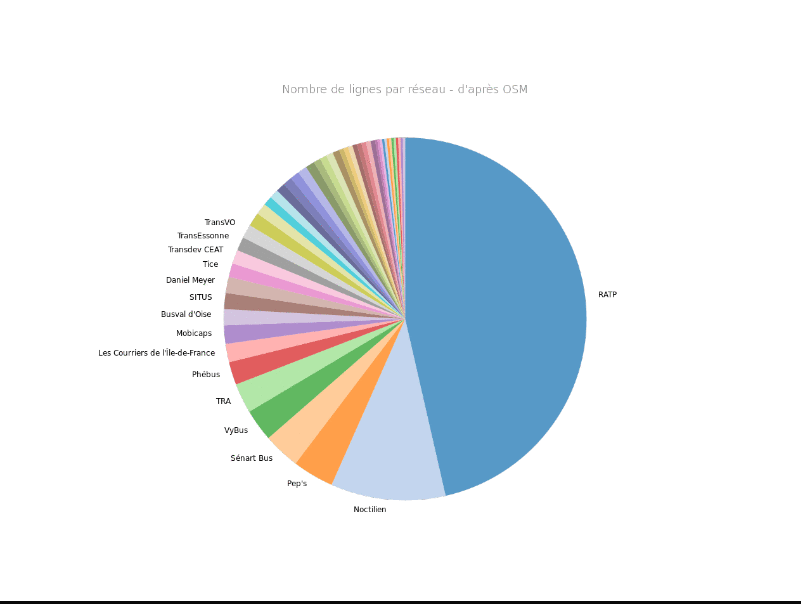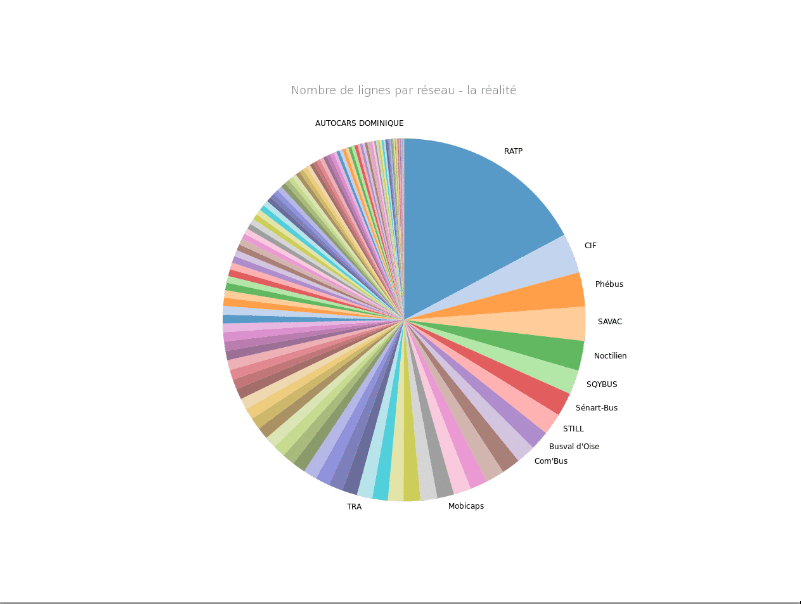 source : données OSM (c) contributeurs OSM / données STIF - navitia.io
source : données OSM (c) contributeurs OSM / données STIF - navitia.io
On a ici une sur-représentation des données RATP et Noctilien, au détriment de la centaine d'autres réseaux qui co-existent en Île-de-France.
Parlons un peu qualité à présent.
Les données OSM sont réputées pour leur qualité, car c'est bien connu, les contributeurs prennent ce sujet très au sérieux.

Le premier indicateur sur lequel OSM brille en général, c'est la précision de la position des arrêts.
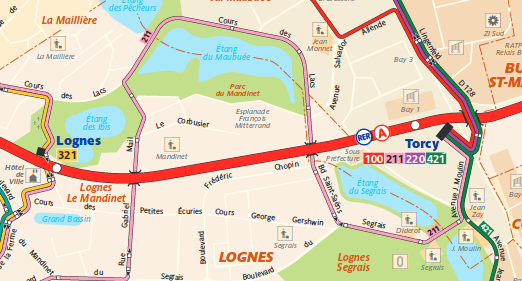
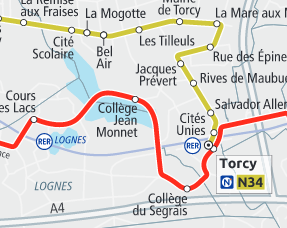
Voici à quoi ressemble la gare routière de Torcy, d'après notre référence, le STIF :
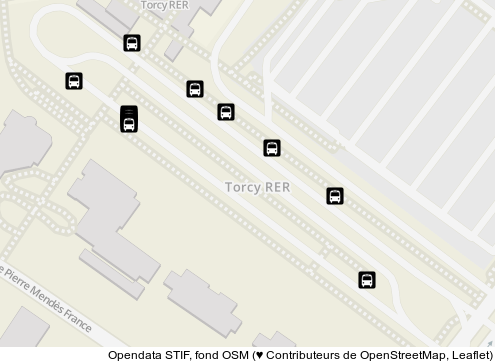
L'accumulation d'arrêts superposés semble peu crédible, mais le reste semble ok.
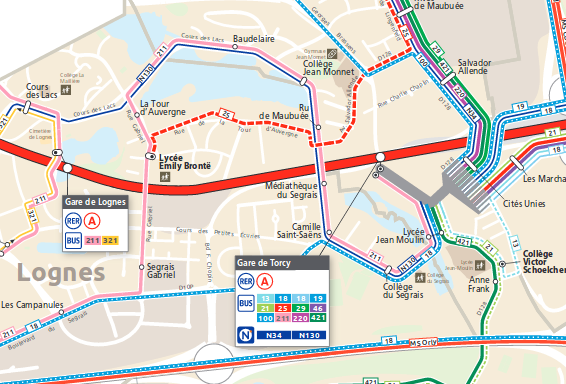
Mais sur le terrain, les arrêts sont régulièrements espacés sur des espaces piétons entourés de voies de bus. Voici à quoi ça ressemble dans OSM, et en réalité :
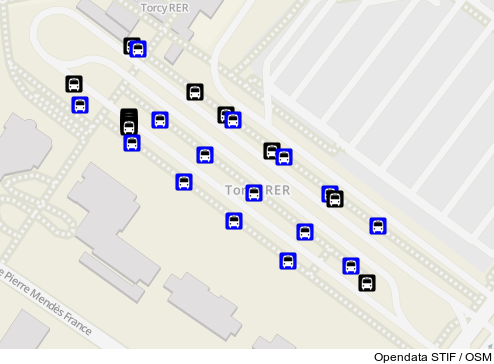
Rien de dramatique à première vue, on pourrait croire que les arrêts sont placés à quelques mètres près.
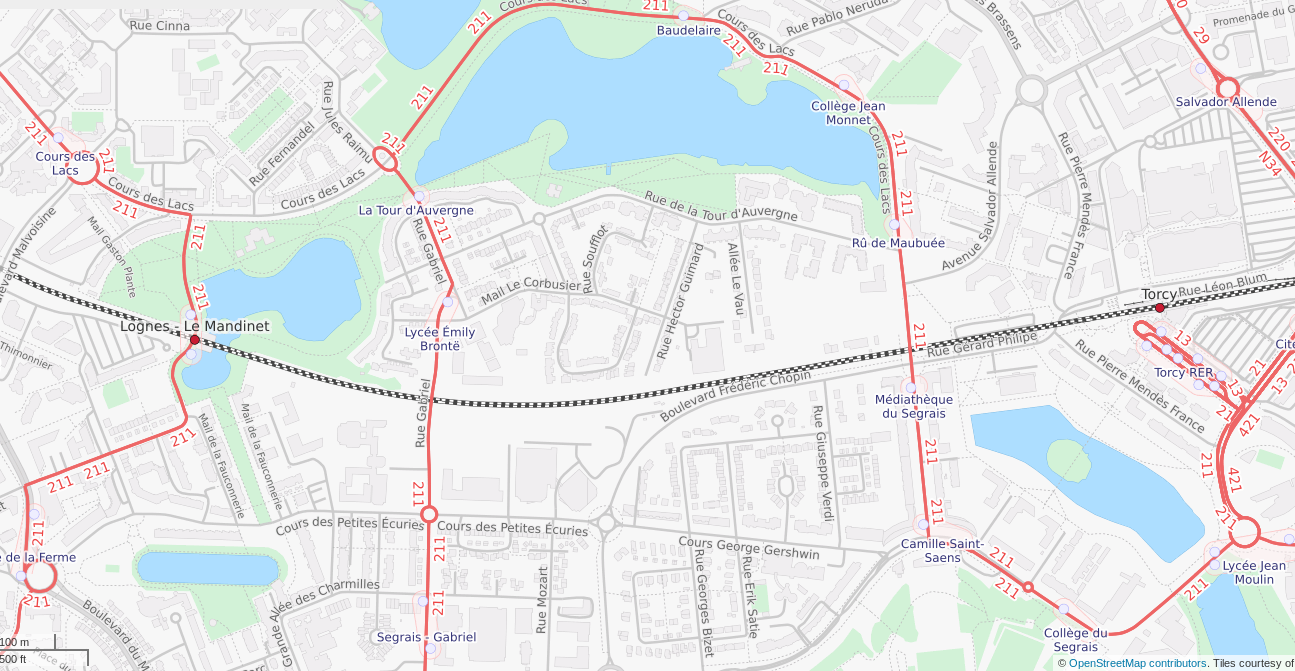
Mais en faisant l'effort de regarder à quel arrêt OSM correspond un arrêt opendata, c'est nettement moins glorieux :
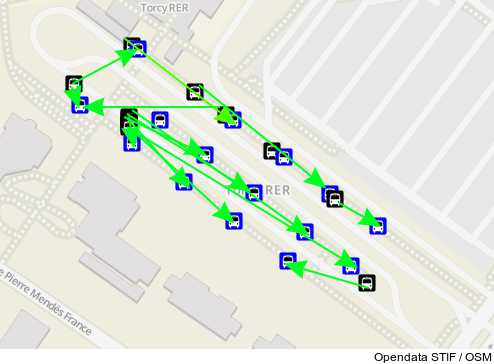
Difficile de trouver un arrêt opendata bien positionné :(
Donc impossible pour un voyageur qui ne connait pas le coin de faire sereinement une correspondance en s'appuyant sur l'information voyageur officielle mise à sa disposition : l'arrêt qu'on lui demande de trouver risque d'être sur le trottoir d'en face voire à l'autre bout de la gare routière ...
Autre point sur lequel OSM se distingue souvent : la réactivité en cas d'évolution sur le réseau.
Il n'est en effet pas rare que les données OSM tiennent compte des nouveaux arrêts et prolongements de lignes un peu avant la mise en service, et plusieurs semaines avec la mise à jour dans l'opendata.
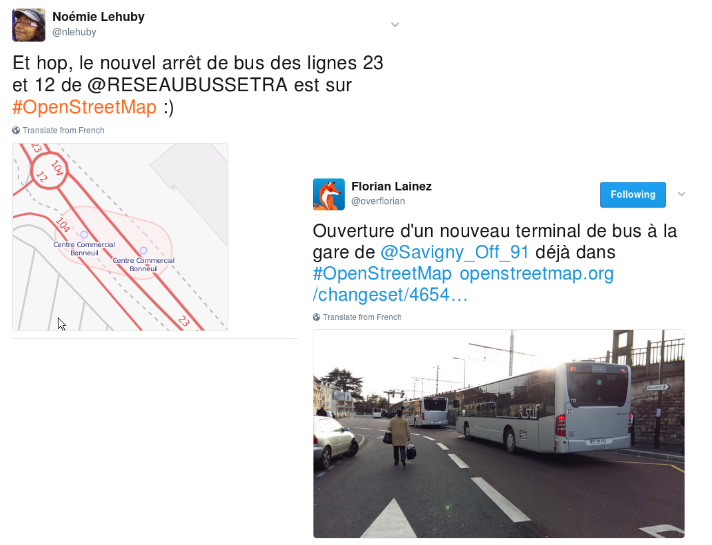 La ligne de tramway 11, dont la mise en service est prévue pour juillet prochain est par exemple déjà en partie dans OSM.
La ligne de tramway 11, dont la mise en service est prévue pour juillet prochain est par exemple déjà en partie dans OSM.
Enfin, un dernier indicateur, un peu plus objectif et global à l'échelle de l'Île-de-France pour sortir du cas particulier dont on sait difficilement s'il est généralisable :
En Île-de-France, chaque arrêt de bus a un nom, ce qui permet de le retrouver sans trop de difficultés sur un plan de ligne ou une grille horaire (même si on retrouve tout de même régulièrement sur le terrain des abribus dépourvus complètement d'information voyageur). Qu'en est-il dans OSM ? Combien d'arrêts ont un nom dans OSM ?
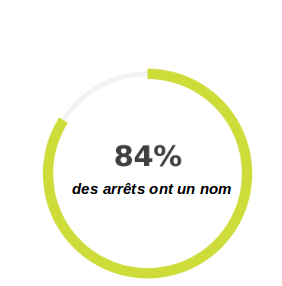
Bref, même si ce n'est pas parfait, OSM semble se distinguer sur la qualité. Mais on l'a vu, côté quantité, plus de la moitié des données est manquante.
Alors quoi ? c'est peine perdue, il faut laisser tomber l'idée de cartographier les réseaux de transport à partir d'OpenStreetMap ?
Non, bien sûr que non, on y croit !
Je sais, depuis longtemps, que cartographier du transport, c'est difficile, j'en ai déjà beaucoup parlé ici sur ce blog.
Et j'ai lancé un projet dans la communauté OSM en décembre dernier, autour du transport en Île-de-France : il s'agit de renseigner les identifiants du référentiel STIF dans les données OSM afin de pouvoir les relier et les comparer plus facilement (Le projet est toujours en cours, rejoignez-le ici)
Ce petit projet a permis de dresser ce constat un peu triste de l'état de la cartographie transport en Île-de-France.
Mais surtout il a permis d'expérimenter des nouvelles choses. Voici quelques petits outils que j'ai pu mettre en place (article plus détaillé à venir ;))
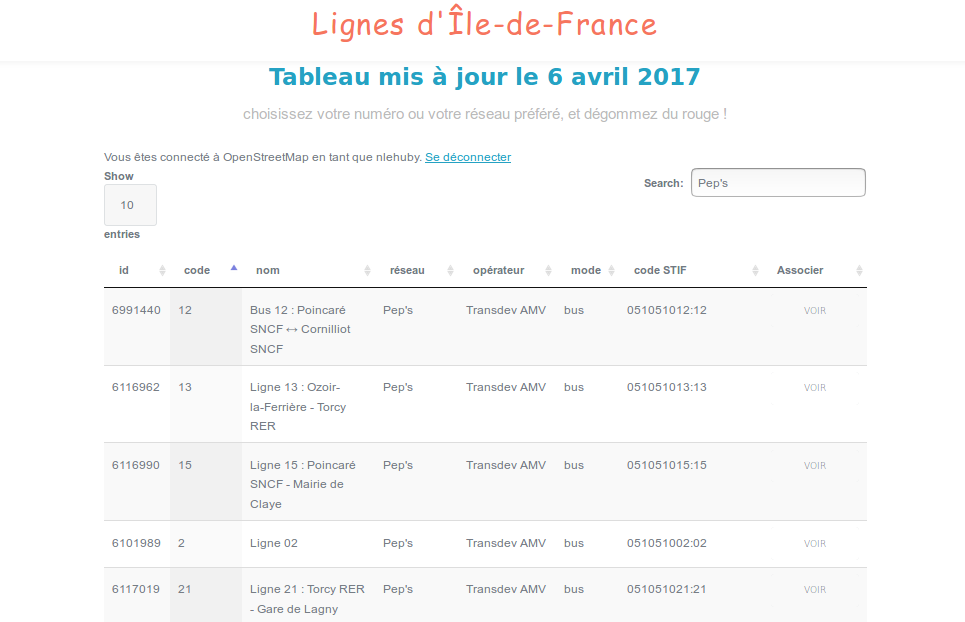
Le rendu de transport n'est pas satisfaisant : on n'arrive pas à savoir si une ligne y est vraiment présente ou pas ?
Tentons une autre forme de représentation : voici une liste. Si tu cherches la ligne 12 du réseau Pep's, cherche "12" ou cherche "Pep's" et tu sauras.
Difficile de savoir si une ligne est déjà bien renseignée ou s'il reste du travail à faire dessus ? Voici une vue qui met en valeur les tracés et les potentiels arrêts non cartographiés en s'appuyant encore une fois sur l'opendata STIF :
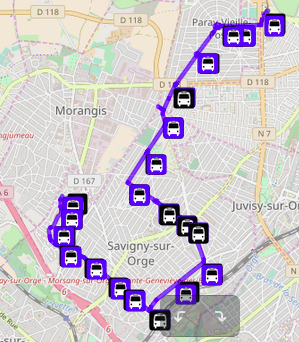
Il est difficile de voir si un arrêt est bien cartographié avec la liste des lignes qui y passent dans OSM. C'est en effet une information un peu complexe à ajouter pour un débutant et non mise en valeur sur les rendus. Voici une vue qui l'affiche explicitement et permet d'ajouter celles qui manquent.
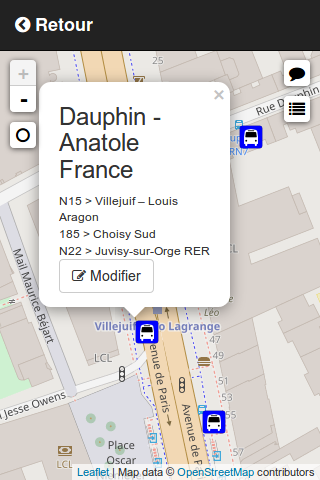
Ajouter un nom sur un arrêt de bus, c'est parfaitement trivial ! Il n'est pas acceptable qu'on ait encore des arrêts de bus sans nom dans OSM.
Voici une solution pour y remédier
Et les résultats sont là : en quelques mois, un travail incroyable a été réalisé :
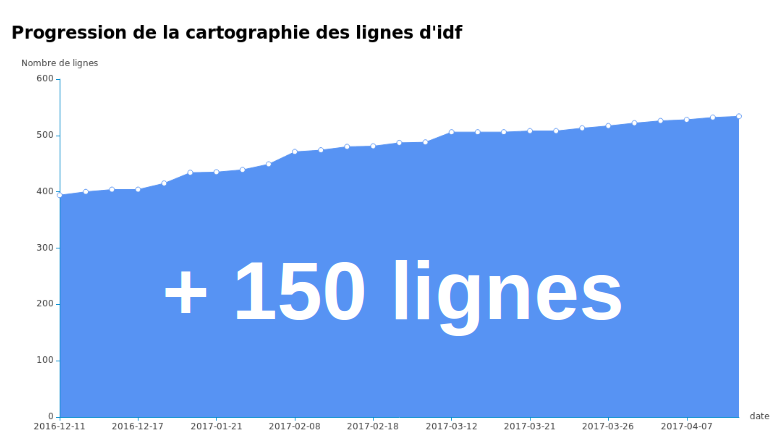
C'est une progression, certes pas fulgurante, mais régulière et significative, qu'on a pu observer ces quelques derniers mois.
Alors oui, en voyant ces résultats, on est rassurés : on peut révolutionner la production des plans de transport avec OSM. Après tout combien de réseaux ont plus de 150 lignes ?
Faisons confiance à la force des contributeurs. Avec les bons outils, on peut y arriver : soutenez le projet Jungle Bus !
Enfin, un dernier point : les données OSM sont aussi en opendata.
Et l'opendata, c'est une opportunité de jouer collectif.
Même s'il y a des trous d'offre, il est déjà possible aujourd'hui, pour un exploitant, un transporteur, une municipalité, etc de regarder ce qu'OSM propose et pourquoi pas d'en tirer parti.
Il est déjà possible d'extraire les positions des arrêts d'OSM pour des comparaisons et pourquoi pas des corrections.
Il est déjà possible, pour les réseaux qui ne présentent que des schémas de lignes en thermomètre peu détaillé de tirer parti des tracés présents dans OSM pour proposer une carte plus détaillée.
Les synergies possibles sont nombreuses, et la communauté Jungle Bus est prête à expérimenter et co-construire afin que les données OpenStreetMap ne soient plus considérées comme une autre base, ou une base concurrente, mais bien comme une base complémentaire, dans laquelle il y a du bon à puiser dès aujourd'hui !
EDIT avril 2018 : Un an plus tard, j'ai co-réalisé pour Jungle Bus un audit comparatif entre les données officielles en opendata et les données OSM sur les bus. N'hésitez pas à le consulter pour encore plus de détails chiffrés.