01 févr. 2015
J'ai déménagé récemment. Et est arrivé le moment où j'ai envie de me
débarrasser des bocaux et bouteilles de verre que j'ai descendus depuis
mon arrivée.
Et surprise, pas de bac de recyclage pour le verre dans ma commune.
Le dépliant sur le recylage m'indique que je dois déposer tout ça dans
l'un des 60 points de collecte de la ville.
Ok, c'est cool, mais ça me fait une belle jambe...
En effet, un container de collecte de verre usagé, c'est un élément de
mobilier urbain qu'on ne remarque que si on est en train d'en chercher
un ... On peut passer à côté tous les jours et ne même pas le remarquer.
Et c'est exatement ce qui m'est arrivé : là comme ça, je serais bien
incapable de savoir où est le plus proche de moi.
Mais là où il y a un problème de données, il y a une solution dans OSM.
Une petite requête overpass plus tard, je découvre que je passe tous les
jours devant un bac de collecte pour aller travailler, et assez
régulièrement devant un second.
Et comme ce n'est pas la première fois que je me retrouve confrontée à
ce genre de situation (par exemple en vacances, loin de chez soi, dans
un endroit où la collecte du verre se fait également dans des bacs
répartis dans la ville) et que je ne suis surement pas la seule à avoir
ce genre de problèmes, je nous ai conconcté une petite carte de tous les
points de collecte du verre cartographiés dans OSM :
Voir en plein
écran
28 janv. 2015
Ce bar, idéalement situé dans le centre de Prague est une étape
obligatoire si vous visitez la ville.
Afficher une carte plus
grande

Ici, des voies ferrées courent entre les tables, voire même au milieu
des tables pour les plus chanceux.


Une fois commandées, les boissons (de préférence des bières, pour donner
dans le local) sont apportées sur des wagons.



Attention cependant à ne pas passer trop de temps à prendre des photos
ou à admirer la figurine du conducteur de train : l’arrêt est marqué
quelques secondes, puis le train repart !


éloignez-vous de la bordure du quai s'il-vous plait
On admirera aussi la signalisation un peu atypique ;)

30 oct. 2014
Si un jour on vous avait dit que vous seriez espionné par votre lampe
de poche, vous auriez crié au Philippe K Dick http://t.co/IFSUJbUYqd

— Jean-noël Lafargue (@Jean_no) October 29, 2014
La lecture récente de ce tweet ainsi que ma participation à l'OpenWorldForum, dont le thème pour cette année était "Take back control", m'ont incitée à écrire cet article que j'avais en tête depuis fort longtemps.
En effet, il y a quelques mois, j'ai voulu télécharger une application de lampe de poche. Un truc tout con qui allume le flash de l'appareil photo en un clic et dont on peut mettre un raccourci sur son bureau. Je me suis donc rendue sur le marché d'application de mon smartphone Android et ai recherché une application répondant à ce besoin.
Et là, j'avoue que j'ai été fort étonnée.
Déjà, par le poids des applications. C'est une info assez peu mise en valeur, il faut chercher un peu pour trouver combien pèse une application. Mais j'ai un passif d'utilisation d'un smartphone low cost, le genre où il faut désinstaller les mises à jour des applications systèmes pour être bien sûr d'avoir assez d'espace dispo pour recevoir ses SMS ... donc c'est une information que je regarde toujours avec attention.
Donc bref, les premières applications proposées pesaient aux alentours de 5 Mo.
J'ai souvenir d'avoir utilisé (en dépannage) une distribution linux complète pesant à peine le double ! M'enfin bref, admettons que je me résigne à en installer une tout de même.
Et là surprise, pour allumer la lampe de mon appareil photo, elle me demande des autorisations tout à fait incongrues telles que l'accès à mes contacts (WTF ??).
Le site Snoopwall a d'ailleurs tout récemment publié un article dressant également ce constat.
En plus parano. Moi, je m'étais naïvement dit que les développeurs avaient dû coder ça dans l'urgence et dans le besoin d'une lampe de poche, et qu'ils avaient oublié de retirer les dépendances et les autorisations non nécessaires ... Ah, l'insouciance du grand public :p
Donc bref, ceci n'est qu'un exemple tout à fait quelconque, mais cela fait réfléchir à ce que les gens mettent dans les applications que nous installons les yeux fermés parce que c'est pratique et que la distribution de nos données privées ne nous tracasse pas plus que ça.
Mais plutôt que de se lamenter, je vous propose de vous parler de deux alternatives, qui apportent des solutions à ces deux problèmes cités plus haut.
Fuir les applis qui nous espionnent
Étonnamment, la solution à ce problème est assez simple. Il se trouve qu'il existe un autre marché d'application, ne proposant que des logiciels opensource et fournissant des indications sur le niveau de confiance que l'on peut attribuer à ces applications. Ça s'appelle F-droid, et c'est téléchargeable et installable sur son téléphone de manière tout à fait triviale.
Ce que j'apprécie particulièrement, c'est le fait qu'il prenne en charge les applications déjà installées.
Par exemple, lorsque j'ai installé F-droid, il m'a indiqué que j'utilisais les applications suivantes qu'il avait lui-même dans sa base d'applications : OSMTracker (une appli de contribution à OSM qu'elle est bien) ou encore Firefox.
Lorsqu'on navigue sur une application, en plus de la description de l'application, il nous propose (en gros, gras et rouge) des avertissements sur l'application. Par exemple, pour Firefox, il me met en garde du fait que "cette application promeut des extensions privatives" (en effet, des addons peuvent être installés, et ne sont pas nécessairement opensource(s?)) et également que "cette application épie et rapporte votre activité (en effet, des stats sont envoyés régulièrement aux développeurs pour améliorer le navigateur ; fonctionnalité bien sur désactivable dans les paramètres).
Nous voilà informés et donc en mesure de faire des choix pertinents !
Quelques points négatifs tout de même : je suis souvent tombée sur des applications peu abouties et où il fallait un peu lutter pour trouver comment ça marche (voire même ce que ça rend comme service).
Ce n'est pas sans rappeler les applications libres d'il y a quelques années, où rien qu'à voir l'IHM, on sentait bien que ça avait été fait par des geeks qui en avaient eu le besoin et non par une entreprise qui fait un logiciel pour rendre un service facturé à des utilisateurs clients ...
Mais pas de généralisation hâtive, on y trouve également quelques applications très satisfaisantes : j'ai par exemple découvert avec surprise Twidere, qui est un client Twitter que j'utilise maintenant régulièrement.
J'y ai également trouvé ma lampe de poche, qui pèse 112 ko (oui oui), est distribuée sous licence Apache 2 et ne demande que l'autorisation d'accéder à mon appareil photo et de bloquer l'extinction automatique de l'écran pendant qu'elle est en cours d'utilisation.
F-droid répond à la problématique des applications qui, sous prétexte de gratuité, bafouent notre droit à la vie privée. Mais ça ne répond pas nécessaire au problèmes des applications codées avec les pieds qui prennent tout l'espace disponible sur le téléphone inutilement.
Pour répondre à ce problème, j'ai trouvé une solution du côté de Mozilla.
Fuir les applications qui pèsent trop lourd
Pour bien comprendre, je pense qu'il est important de resituer le contexte. Contrairement à ce qu'on pourrait naïvement penser, Mozilla est une fondation qui a pour objectif, non pas de conquérir le monde avec un navigateur qui ressemble à un renard de feu / un panda roux. Non, Mozilla a pour but de favoriser l'accès à internet. De désenclaver les utilisateurs enfermés dans leurs systèmes privateurs en leur offrant un accès universel (notemment via le web).
Le navigateur Firefox est un outil qui répond très bien à ce besoin.
Thunderbird également, en nous rappelant que le mail est un outil de communication et non un logiciel Microsoft ou une IHM web de Google.
Et pour le mobile, les applications Firefox pour Android répondent également à ce besoin.
En effet, ces applications sont des encapsulations d'applications web qui s'installent et s'utilisent comme des vraies applications Android.
L'intégration des ces applications dans l'éco-système Android est réellement bluffant : ces applications
- s'installent comme des app android à partir d'un marché d'applications
- sont listées avec les autres applications dans le système
- se mettent à jour comme les autres applications
[EDIT 2016 : Mozilla a mis fin à ce programme, il n'est plus possible d'installer sur Android des applications FirefoxOS avec Firefox pour Android. Mais les applications Firefox OS qui sont des réelles appli web restent utilisables sur Android (c'est le cas d'OpenBeerMap)]
Une fois installées, il est même parfois difficile de les différencier des autres. Ici, OpenBeerMap, installée sur un Android depuis le marché d'application de Firefox :

Un point important à noter : ces applications peuvent fonctionner hors ligne (si elles sont bien foutues. Pas OpenBeerMap, donc). Ce sont les technologies du web, mais ça ne veut pas forcément dire qu'un accès au web est nécessaire à tout moment.
Bon ok c'est cool me diriez-vous, mais une application, en général, ça rend un service un peu plus avancé qu'un site web. Effectivement, mais Mozilla a aussi une réponse pour ça : des API d'accès au matériel sont en développement et en cours de standardisation.
Elles permettent donc à des applications web d'accéder à l'appareil photo ou aux contacts, d'afficher des notifications ou de faire vibrer le téléphone.
L'implémentation effective de ces APIs est encore au stade expérimental mais il y a déjà des choses sympa qui fonctionnent et on a déjà des services efficaces proposés ainsi.
Les applications sont téléchargeables sur le marché d'application de Firefox OS, le système d'exploitation basé sur les technologies du web que Mozilla a lancé il y a quelques années et qui a débarqué en France depuis quelques mois.
Par exemple, l'application de prise de notes de mon téléphone est une application Firefox pour Android
Elle fonctionne parfaitement hors ligne et sauvegarde en local les notes que je prends.
Elle permet également un stockage dans le cloud, pour permettre d'utiliser l'application depuis plusieurs terminaux.
Sans mentir, c'est sans doute une des meilleures appli de prise de note que j'ai testées sous Android.
C'est aussi sur le marché d'application de Firefox OS que j'ai trouvé l'application de météo que j'utilise au quotidien : l'appli F&C
Avec un design simplifié au max mais néanmoins convaincant et terriblement efficace, elle permet d'avoir une tendance sur la météo. Et elle pèse environ 350 Ko (dont la moitié occupée par des données, telles que les endroits où j'ai voulu connaitre la météo et que j'ai sauvegardés).

Ces applications battent des records de poids. Mais pour le moment, elles ne répondent pas à ma première problématique et il est aujourd'hui difficile de savoir si elles sont utilisées pour collecter des données sur leurs utilisateurs.
Espérons qu'une solution adressant ces deux problématiques verra le jour prochainement.
05 juil. 2014
Ce samedi, c'était la chasse aux trésors de
Paris !
Mes acolytes et moi nous sommes donc lancés sur la trace d'Érasme et de
sa bien aimée !
Voir en plein écran
20 juin 2014
S’il y a une région qui se prête particulièrement aux railtrips comme je
les aime, c’est bien la région PACA.
Je ne cesse de m’émerveiller de tout ce qu’on peut voir et faire en
prenant un TER à moins de 5 euros.

J’ai en effet profité du week-end de l’ascension pour réaliser deux
petits railtrip fort sympathiques, quoique, pour changer, j’ai encore eu
des grands moments de solitude face aux bornes de vente de billets.
Départ d’Antibes, direction Beaulieu-sur-Mer pour une petite promenade
le long de la mer, vers randonnée vers St-Jean-Cap-Ferrat
Direction les bornes pour acheter des billets.
Pour ma part, je me dirige vers la borne classique qui vend des billets
pour les trains grandes lignes mais aussi les TER (les jaunes moches
habituelles) pour acheter deux billets (pour un de mes acolytes et
moi-même)
Je saisis mes 342 options nécessaires jusqu’à arriver au moment où il
faut saisir son numéro de carte voyageur ou son numéro de carte jeune.
Mon acolyte commence à farfouiller dans ses affaires, ça traine ça
traine et loupé ! il faut tout recommencer depuis le début.
Vu que les autres acolytes ont libéré une borne TER, je migre vers
celle-ci car j’ai souvenir qu’elles sont plus simples à utiliser.
Là effectivement, il n’est pas nécessaire de donner son numéro de carte
voyageur (de toute manière, avec un billet si peu cher, on ne cumule
même pas de points de fidélité !), je passe sans encombre l’étape du
choix de la zone (bleue ou blanche) grâce à l’étiquette positionnée
au-dessus de l’écran (pas comme à Banyuls-Sur-Mer) et j’arrive
rapidement au moment où il faut payer. Là, dans la précipitation, je me
trompe et je mets ma carte bancaire dans la fente réservée à une autre
carte (carte d’abonné TER ? je ne sais plus). Argh, la borne plante. Il
faut attendre qu’elle redémarre.
Bon aller, troisième essai, cette fois-ci c’est la bonne, je suis
finalement en possession de mes deux billets. Comme vous pouvez le voir,
j’ai toujours autant de mal à utiliser les bornes SNCF …
Compostage, et direction la plage !
La petite promenade en train est assez rapide, et laisse place à une
vraie promenade sur le littoral, entre la mer et les montagnes.

Sur le chemin, nous apercevons, entre autres, le village perché d’Èze,
où nous allons le lendemain !
Je vous épargne les détails, passons directement au lendemain.
De même, tout commence dans la gare d’Antibes, au moment d’acheter son
billet de TER.
Rebelote, je sélectionne les options, je cherche la zone, etc. Au bout
de quelques étapes, je me rends compte que je me suis gourée : j’ai
sélectionnée 12/25 découverte au lieu de carte jeune : je recommence
tout.
Pour rien, visiblement, c’est le même prix.
Mais impossible cette fois d’acheter plusieurs billets en même temps …
zut, les bornes se ressemblent mais ne sont pas exactement les mêmes.
Je ne voudrais pas lancer une théorie du complot mais quand même, si on
avait voulu rendre l’achat de billet de train compliqué, on ne s’y
serait probablement pas pris autrement.
Bref, je refais tout deux fois, et c’est parti !
Ou pas, vu que le prochain train est en fait dans une heure.
Du coup, j’ai proposé à mes acolytes de cartographier sur OSM
l’accessibilité de la gare d’Antibes mais étonnement, la proposition de
la partie de UNO sur la plage a obtenu plus de suffrages …
Comme la plage d’Antibes est un peu loin de la gare, nous décidons
d’aller plutôt à la plage sur une gare de notre parcours. En effet, avec
une sortie située à quelques dizaines de mètres de la plage, c’est la
gare de Biot qui maximise le temps passé à attraper des coups de soleils
en mangeant des +4.
Bon, là en théorie, on aurait dû reprendre des tickets car apparemment,
deux tickets A vers B puis B vers C, ça coute plus cher qu’un ticket A
vers C.
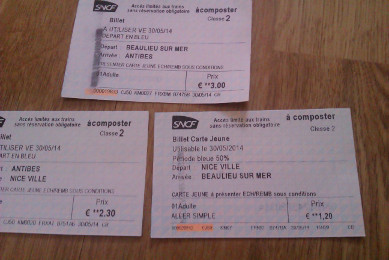
Mais bon, le guichet est squatté par des étrangers qui vont surement à
Monaco, et le temps qu’on trouve un moyen d’échanger les billets déjà
achetés contre les nouveaux sur une borne, c’est sûr qu’on risque de ne
plus faire ni plage ni UNO, et qu’on va rater le fameux train pour
lequel on a initialement pris un billet !
Donc bref, on monte dans le premier train et va se couvrir les fesses de
la poussière blanche de la plage de Biot, puis on reprend notre train
initial et on arrive finalement à Èze !
On se trompe de sortie, on traverse les voies sur un passage à niveau
puis on arrive finalement devant un restaurant. Ça tombe bien, cette
matinée nous a épuisé et nous avons besoin de nous restaurer pour
attaquer l’ascension de Èze par le chemin de Nietzche.
Mais surprise, il se met à pleuvoir …
On attends donc et on en profite pour prendre entrée, plat, dessert,
café et faire des pyramides de sucre.
Ça ne se calme pas, on commence à envisager l’option retour sans rando …
Un bus passe très régulièrement et s’arrête pas très loin, et il semble
aller dans la bonne direction.
Je tente de regarder ses horaires sur mon smartphone low cost : hum, pas
de Centrale de Mobilité dans cette région, pas de système d’information
multimodale régional, il faut que je me tape le site pas du tout adapté
des cars départementaux.
Comme d’habitude, ça fonctionne pas super, on laisse tomber et on se
rabat sur notre ami le train …
Mais au moment où on se décide à partir, la pluie se calme enfin : go go
go !
Nous attaquons donc une ballade très sympathique, d’une grosse
demi-heure..
La vue est magnifique : le regard d’un de mes acolyte s’arrête sur les
falaises, le mien sur la ligne de chemin de fer qui longe la mer ...


Le parcours est bien indiqué, et jalonné de passages informatifs sur
Nietzche qui aurait écrit son fameux bouquin dans ces lieux.

Bien indiqué, bien indiqué … pas partout quand même
Et la randonnée s’achève dans une petite cité médiévale de rues pavées
et de galeries d’art.
Nous trainassons un peu puis prenons le chemin du retour.

À mi-parcours, nous regardons les horaires du prochain TER qui nous
ramène à Antibes et … on se met à courir vers la gare.
Ça me rappelle une idée sur laquelle j’avais bossée dans un hackathon,
pour proposer, entre autres, des trajets TER + rando + TER, en
optimisant les temps pour ne pas se retrouver à courir pour avoir son
train, ou à l’inverse à attendre deux heures à la gare parce qu’on l’a
loupé …