24 juil. 2016
Quand on souhaite réaliser une analyse thématique à partir des données OSM, on passe forcément par l'étape de récupération des données.
Pour cela, on a plusieurs solutions.
La plus simple pour se lancer, c'est d'utiliser Overpass, via Overpass Turbo.
J'en ai déjà parlé dans un précédent article : on donne nos contraintes et en un rien de temps, on a un résultat visuel et les objets qui nous intéressent ressortent sur la carte.
On peut alors récupérer directement ces objets ou bien la requête Overpass pour la faire exécuter par un autre applicatif (comme uMap par exemple, cf mon tutoriel sur le sujet)
À noter que l'API Overpass permet également de récupérer des objets au format csv, ce qui peut s'avérer pratique s'il s'agit d'une extraction pour analyse (et pas juste pour un affichage). Voici par exemple le nécessaire pour récupérer dans Overpass-Turbo les distributeurs de billets alentours, en csv :
[out:csv(::"id", ::lat, ::lon, operator)][timeout:25];
(
node["amenity"="atm"]({{bbox}});
);
out ;
Bref, malgré une courbe d'apprentissage de la syntaxe un peu rude (Overpass Turbo et le wiki sont là pour aider), Overpass, c'est génial !
Cependant, dès qu'on souhaite requêter une trop grande quantité de données, une trop grande surface ou à une fréquence trop élevée, on se retrouve confrontés aux limites de l'API.
Dans ce cas de figure, la solution royale, c'est de récupérer directement toutes les données brutes d'OSM et de faire sa propre extraction à la main.
En général, on télécharge les données, au format pbf, sur Geofabrik par exemple.
Puis, une solution courante est d'insérer ces données en base (avec imposm ou osm2pgsql), puis de faire des requêtes SQL pour extraire les infos souhaitées.
Mais, lorsque l'extraction est assez simple, sachez qu'il existe une alternative en ligne de commande, basée sur Osmosis et Osmconvert.
On utilisera osmosis pour ne conserver dans les données que les objets qui nous intéressent.
Puis on utilisera osmconvert pour extraire ces objets au format csv.
Par exemple, si je souhaite extraire tous les distributeurs de billets (amenity = atm) des données OSM que j'ai téléchargées, je peux procéder ainsi :
osmosis --read-pbf file="data.osm.pbf" --nkv keyValueList="amenity.atm" --write-pbf atm.osm.pbf
À ce stade, j'ai obtenu un fichier pbf ne contenant que les noeuds taggés avec amenity = atm. Puis, pour avoir tout ça dans un format plus habituel et extraire uniquement les tags qui m'intéressent :
osmconvert atm.osm.pbf --csv="@id @lat @lon name operator network fee" --csv-headline --csv-separator=";" -o=osm_atm.csv
Et je peux aussi réaliser des unions : par exemple, admettons que je souhaite également récupérer les horloges publiques (amenity = clock) pour réaliser une analyse particulièrement innovante sur les distributeurs et les horloges ...
Je commence par procéder de même :
osmosis --read-pbf file="data.osm.pbf" --nkv keyValueList="amenity.clock" --write-pbf clock.osm.pbf
Puis, je fusionne mes deux fichiers précédemment obtenus en un seul :
osmosis --read-pbf atm.osm.pbf --read-pbf clock.osm.pbf --merge --write-pbf clock_and_atm.osm.pbf
Puis, je peux, comme précédemment utiliser osmconvert pour récupérer les objets et les tags utiles.
À noter que si on souhaite extraire autre chose que des noeuds, il reste possible d'utiliser osmosis, mais c'est un peu plus complexe.
La requête suivante permet par exemple de récupérer les parcours de bus (qui sont des relations taggées avec route=bus) :
osmosis --read-pbf data.osm.pbf --tf accept-relations route=bus --used-way --used-node --write-pbf route_bus.osm.pbf
On a alors un pbf contenant les relations parcours de bus, ainsi que tous les objets (chemins et noeuds) qui constituent ces relations.
13 juin 2016
Après quelques années de bons et loyaux services, mon hébergeur DrupalGardens jette l'éponge. C'est pour moi l'occasion de déménager mon blog vers 5apps, et j'en profite au passage pour le migrer de Drupal vers Pelican.
Drupal c'est cool. Je suis tombée dedans il y a longtemps, alors que j'étais encore en école d'ingé, et j'ai même eu l'occasion de m'impliquer dans la communauté francophone de Drupal pendant quelques années.
Mais faire mon blog avec Drupal, c'est un peu comme louer une cuisine professionnelle pour se faire un oeuf sur le plat : ça marche, mais pour le KISS, on repassera.
Donc j'ai décidé de passer à un site statique.
Pelican, c'est assez fun à utiliser : on écrit ses articles en rst ou en markdown, puis pélican compile / transforme tout ça en pages html, qu'on peut héberger très simplement puisque c'est juste du html tout con.
Un peu comme Sphinx, mais pour un blog.
Quelques détails sur la migration :
J'ai commencé par installer Pelican. Ça s'installe en local (voir à ce propos le très bon article de SpF sur ce sujet) et c'est sans difficicultés particulières.
Ensuite, j'ai migré le contenu existant en utilisant l'import par flux RSS.
C'est loin d'être parfait : j'ai dû repasser sur tous les articles pour virer les balises html en trop dans le fichier md généré... C'est là que je suis bien contente de n'avoir que 24 articles publiés !
Mais ça m'a permis d'avoir une nouvelle instance de blog qui tourne en quelques heures, avec tous mes anciens contenus.
Bon, ce n'est qu'une façade, car tous les liens pointent encore sur l'ancien site, ainsi que les images, mais bon si les migrations entre services étaient si faciles, ça se saurait ;)
Pour l'hébergement, J'ai choisi 5apps.com, car je l'utilise déjà pour héberger mes petites appli en html (dont Horaires-Bus, mon appli pour consulter les horaires des bus même quand y a plus de réseau) et j'en suis très satisfaite.
C'est aussi simple à utiliser qu'un hébergement web chez github (on fait git push pour déployer), mais avec des services sympa en plus (notamment la génération automatique d'AppCache. Si vous utilisez cette techno et que je vous le faites à la mano, je pense que vous voyez pourquoi c'est cool :p)
Bref, je vais m'arrêter là, parce que j'ai toujours trouvé ça très méta les gens qui tiennent un blog pour ... parler de leur blog.
Tout ça pour dire que la nouvelle adresse de ce blog est https://nlehuby.5apps.com (ou https://nlehuby.5apps.com/feeds/all.atom.xml pour les lecteurs de flux)
13 mai 2016
Il y a deux ans, je voulais visualiser et modifier dans OSM les tags
spécifiant les bières pression servies dans les
bars.
Et c'était galère, alors j'ai fait un outil pour ça : l'aventure
OpenBeerMap a commencé.
Puis, il y a à peu près un an, j'ai voulu visualiser dans OSM où
déposer mes déchets en verre pour les
recycler.
Et c'était galère, alors j'ai fait un tuto expliquant comment faire une
carte
dynamique
pour afficher facilement des données OSM.
Les choses bougent vite, la communauté OSM est très active : maintenant,
il est devenu plutôt facile de réaliser ce genre de carte.
Je le dis, je le prouve : voici une carte des bouches de métro, avec un
code couleur selon la complétude de l'info, réalisée en 10 minutes top
chrono
L'outil qui a permis cela s'appelle
MapContrib, et son job est
de fabriquer des cartes dynamiques à partir des données OSM.
Et il permet également de modifier les données OSM affichées directement
depuis la carte générée, de manière simple et efficace.
Si vous avez suivi mon tuto
précédent,
vous pouvez prendre en main MapContrib en un temps record : le concept
est très similaire, on crée des calques de données, dans lequel on met
une requête Overpass et ça marche tout seul.
Un peu de personalisation des marqueurs et hop, on a une carte
partageable à diffuser à nos contributeurs !
Bref, plus le temps passe et moins vous avez d'excuses pour ne pas
contribuer à OpenStreetMap ;)
11 juin 2015
Je me suis enfin décidée à publier ma deuxième application
FirefoxOS.
Elle a une mission très simple : sauvegarder et restituer les horaires
théoriques de passage de bus à un arrêt.
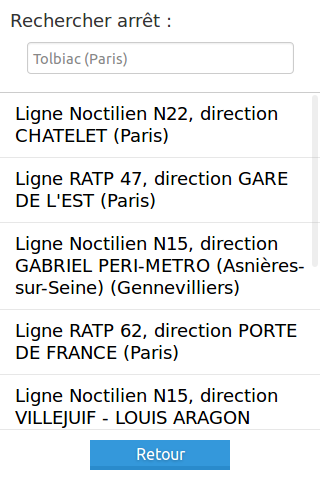
Son fonctionnement est simple : en deux étapes
l'initialisation (quand j'ai une connexion internet)
- je choisis mon arrêt.
- je sélectionne la ligne et la direction
- je vois alors les horaires, et je peux les enregistrer
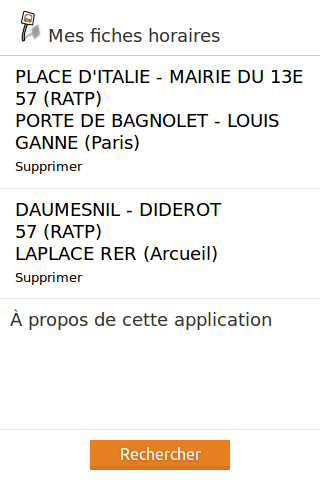
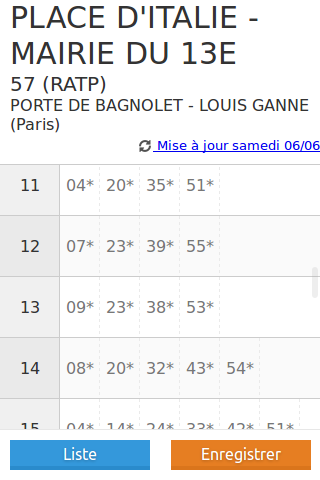
l'utilisation (quand je suis en déplacement, potentiellement sans
connexion internet)
- je vois la liste de mes fiches horaires enregistrées
- je sélectionne celle que je veux, et je consulte les horaires
Cette application utilise les données opendata d'Île-de-France, grâce à
l'API navitia.io
Si vous voulez l'utiliser ailleurs, faites-moi signe : si votre région
est couverte par navitia.io, je peux vous en déployer une version avec
les horaires qui vous intéressent.
Cette application a été initiée pendant un hackathon chez Mozilla Paris
en novembre 2014, puis peufinée par mes soins avec plus ou moins
d'assiduité et de motivation pendant plusieurs mois.
C'est bien sûr open-source si vous voulez contribuer au code ou
remonter des bugs. Si
vous voulez supporter le coût de développement (énorme !) de l'appli,
j'accepte les
Flattries
(et les bières, toujours).
Le but initial était de pouvoir avoir toujours sur moi les horaires de
mon bus de banlieue peu fréquent, pour adapter mon itinéraire en
connaissance de cause, et ce même si ça ne capte pas ...
Dans la pratique, j'ai déménagé depuis et ne prends plus ce bus de
banlieue, et ses horaires ne sont toujours pas en opendata, donc
j'aurais une utilisation assez limitée de l'application.
EDIT : le STIF a ouvert les données transport théoriques de toute
l'Île-de-France donc ... l'appli fonctionne à présent sur les bus de
banlieue !
J'espère que d'autres en auront l'usage ou sauront s'en inspirer pour
d'autres utilisations.
23 févr. 2015
Ce que j’apprécie particulièrement avec OpenStreetMap, c’est que c’est
un écosystème très riche et qu’on peut découvrir chaque jour un nouveau
truc génial à faire avec.
Voici un petit exemple d’une fonctionnalité que j’ai découverte
récemment, et utilisée dans mon précédent article sur les points de
collecte de recyclage de
verre.
EDIT 2019 - cet article est un peu daté. Voir aussi le tutoriel de fgouget sur le même thème : Comment j'ai créé une carte mondiale des boîtes à livres en quelques minutes
OpenStreetMap, c’est avant tout une grosse base de données. Mais pour
mettre en évidence ces données, il faut avoir un certain niveau de
connaissance d’OpenStreetMap.
Voici un solution simple pour afficher des données issues de la base OSM
sur un fond de carte (OSM, évidemment), avec mise à jour automatique des
données en fonction des modifications apportées sur la base par les
contributeurs.
Voir en plein
écran
Ici, une carte des boulangeries de Paris présentes dans OSM.
Pour récupérer les données, on utilisera par exemple l’API Overpass.
Et comme faire une requête Overpass qui fonctionne du premier coup est
une opération un peu hasardeuse, on utilisera bien sûr Overpass
Turbo.
Le tag pour une boulangerie est le suivant : shop =
bakery
En utilisant le wizard d'Overpass Turbo, on obtient le résultat
suivant :
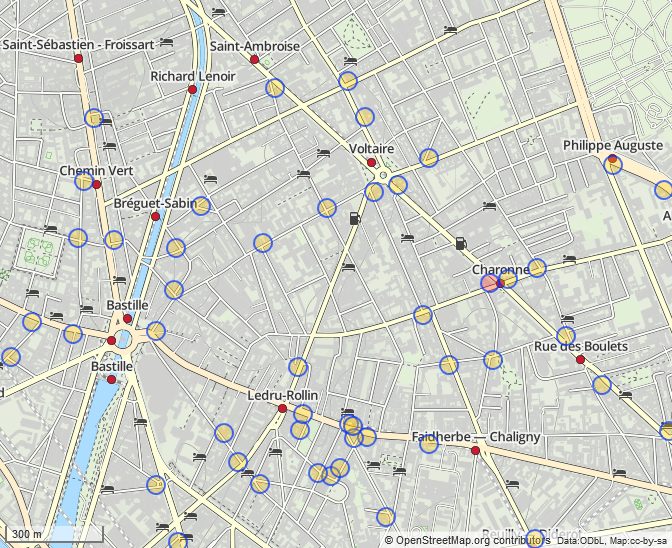
Le résultat est ok, mais un peu moche.
Pour aller plus loin, on va afficher ces données dans
uMap, un service opensource de
création de carte personnalisable simple d’accès.
uMap permet en effet de choisir un fond de carte OSM et d’y ajouter des
données de la provenance de son choix, de personnaliser un peu le design
général, puis de partager sa carte.
Il nous faut donc indiquer à uMap où trouver les données à afficher.
Pour cela, dans Overpass Turbo : Exporter > Requête > format compact
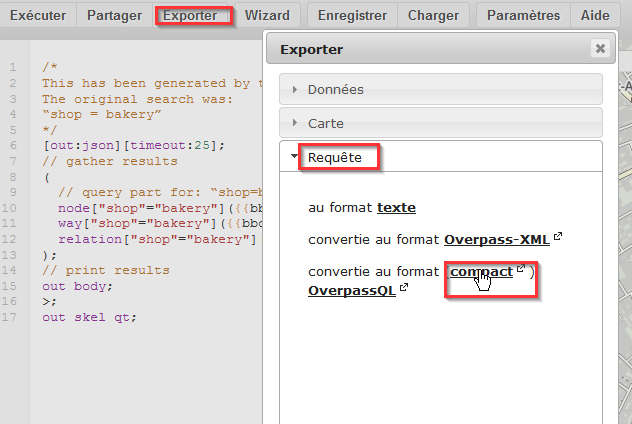
On obtient alors les paramètres, sous un format compact, à passer à
l’API Overpass pour avoir un résultat.
Pour obtenir ce résultat, il faut passer ces paramètres à une instance
Overpass (par exemple, l’instance mondiale
« principale » ou
l’instance française).
En concaténant les deux bouts de mon url, j’ai une requête que me
retourne les données OSM au format json :
http://api.openstreetmap.fr/oapi/interpreter?data=[out:json][timeout:25]...
Muni de cette précieuse requête, allons sur uMap créer notre jolie
carte !
Sur une carte, les données sont regroupées par « calque ».
Créons une carte.
Par défaut, elle contient un seul calque, vide, appelé calque 1.
Nous allons éditer ce calque pour y ajouter nos données récupérées via
Overpass
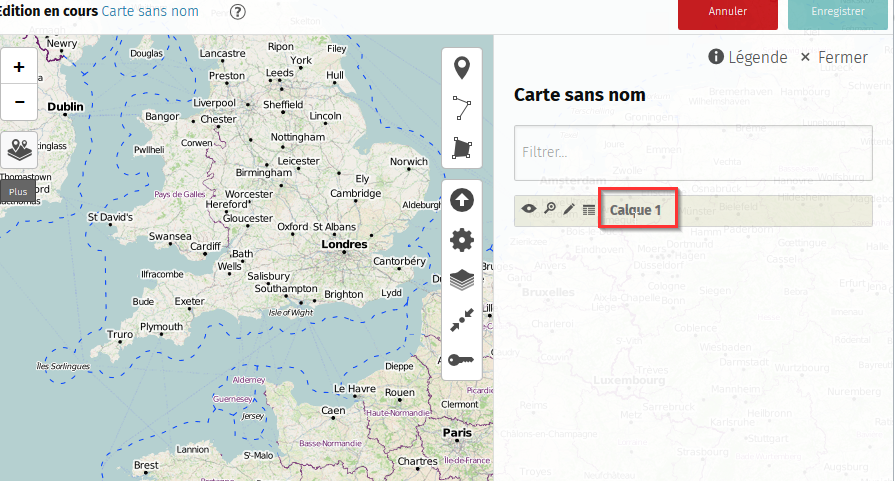
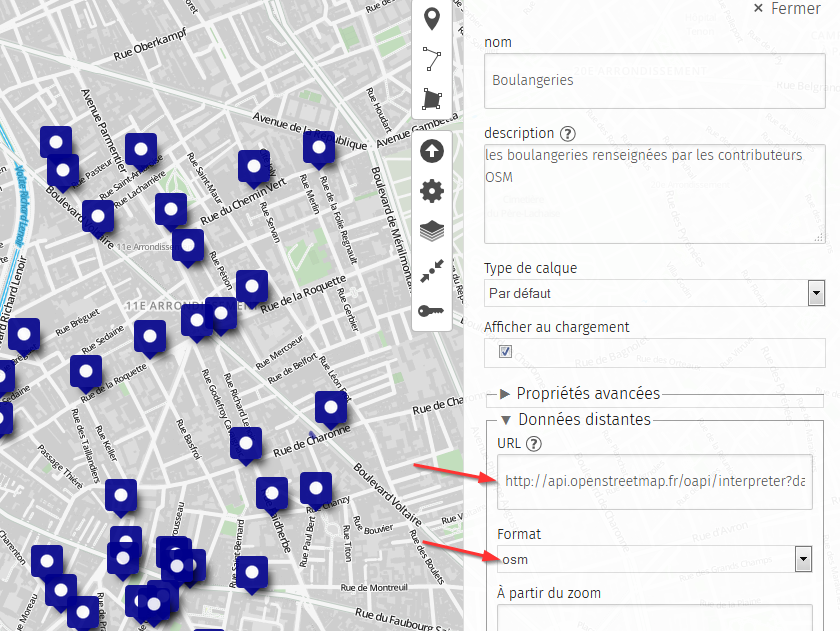
Cliquons sur Données distantes
Dans le champ url, renseigner la requête Overpass, et sélectionner le
format de données « osm »
Enfin, cocher la case « Dynamique »
Vous devriez voir vos données s’afficher sur la carte.
C’est bien, mais … on peut mieux faire !
En effet, on aimerait bien pouvoir se déplacer sur la carte pour voir
les boulangeries ailleurs que sur le petit coin que j’ai choisi.
Il faut donc indiquer à uMap de modifier la requête Overpass en fonction
de l’endroit où se situe l’utilisateur sur la carte.
Cela se fait très simplement en remplacer toutes les occurrences des
coordonnées dans la requête par les mots-clefs suivants
{south},{west},{north},{east} qui sont interprétés par uMap.
La requête Overpass devient alors :
https://overpass-api.de/api/interpreter?data=[out:json][timeout:25];(node["shop"="bakery"]({south},{west},{north},{east});way["shop"="bakery"]({south},{west},{north},{east});relation["shop"="bakery"]({south},{west},{north},{east}););out body;>;out skel qt;
Il ne reste plus qu’à personnaliser la carte selon nos goûts, nos envies
et nos besoins : on peut changer le fond de carte, choisir des marqueurs
plus jolis, etc
Ne pas oublier également de préciser la licence (ODbL, car utilisation
de données OSM).
Puis, il ne reste plus qu’à partager sa carte avec le monde entier.
Pour cela, on peut soit fournir un
lien,
soit l’embarquer directement dans la page comme je l’ai fait ici
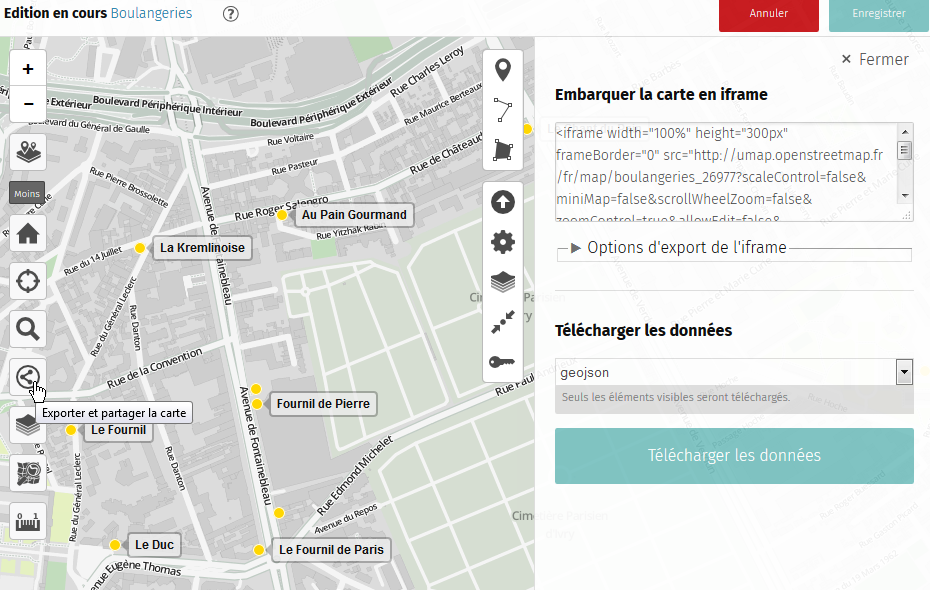
Et voilà. C’est simple et efficace :)
Si vous avez des besoins plus sophistiqués, il faudra coder un peu et
partir sur des solutions à bases de modules de Leaflet, telles que
celles que j’ai mises en place pour
OpenBeerMap.