12 juin 2014
Comme je me suis lancée récemment dans l'internationalisation (je l'ai
écrit une fois, maintenant, ça sera i18n et puis c'est tout) de mon
petit site OpenBeerMap, et comme
c'est ma première expérience en tant que développeur sur ce sujet et que
j'ai vraiment galéré, je vous propose un article à mi-parcours entre le
tutoriel et le retour d'expérience sur l'utilisation de l20n en
javascript.
Comment j'ai pas tout bien compris, si vous avez des retours et repérez
des erreurs, n'hésitez pas à me le signaler ;)
Commençons par les basiques : c'est quoi ?
L'i18n, c'est tout simplement avoir du texte adapté à la langue de la
personne qui utilise le site ou le appli. Mais ce n'est pas tout, c'est
aussi respecter les conventions propres à un pays (voire une région) par
exemple le format de date.
Il existe des bibliothèques dans un peu tous les langages de
programmation pour réaliser ceci. Mon site étant en html et javascript,
j'ai opté pour une bibliothèque js.
Bon, j'ai pas choisi la plus facile mais j'avais envie d'expérimenter la
solution Mozilla : l20n.
En particulier, le format des fichiers de traduction permet de gérer des
tas de choses qui doivent donner bien mal à la tête en temps normal,
comme par exemple les langues avec des déclinaisons (l'allemand, le
polonais, etc), les pluriels (qui s'expriment potentiellement
différemment dans les différentes langues), etc. Mais ... je ne vous
parlerai pas de ça dans cet article : la documentation sur le super
format de fichiers de traduction est abondante et facile à trouver. Je
vais "seulement" vous montrer comment commencer l'i18n d'un site et
arriver au moment où vous écrivez ces fichiers de traduction au format
si merveilleux.
Comment ça fonctionne ?
Un peu de théorie avant de partir tête baissée !
L'idée de base, c'est que l20n recherche tous les éléments textuels
qu'on a identifié comme à traduire, puis les remplace par leur valeur
dans la langue que le navigateur web lui demande d'utiliser, ou par
une valeur dans la langue par défaut (ou par une clef de traduction si
la valeur n'a pas été renseignée nulle part).
Bon, j'avoue que sur la partie en italique : c'est une approximation ...
Il y a moyen de raffiner énormément avec l'API de l20n mais 1) j'ai rien
compris et 2) pour commencer, la langue du navigateur, c'est déjà pas
mal et ça couvre l'essentiel des besoins.
En bref, l20n repasse sur toute la page HTML une fois qu'elle est
affichée entièrement et remplace le texte par les traductions donc
- le texte écrit dans le HTML ne sert à rien : on peut mettre lorem
ipsum à la place, ça marche tout aussi bien
- si le traducteur d'une langue qu'on ne maitrise pas veut nous faire
un coup bas, il ya surement moyen d'injecter du code malicieux dans
les traductions et de le voir interprété par l20n ... mais bon, il
parait qu'ils ont pris leur précaution, ça doit être mon côté parano
...
- si y a des bouts de HTML qui sont ajoutés dynamiquement par du
javascript, ben ... ça va pas être évident, il faudra demander
spécifiquement la traduction à la l20n au moment où on ajoute ce
texte dynamique !
Allons-y !
Prenons donc notre super site en HTML et javascript, et introduisons un
peu de l20n dedans !
Première étape : ajouter l20n.js à la liste des scripts à
exécuter
<script src="l20n.js"></script>
Étape 1 bis : trouver une version de l20n.js qui fonctionne
ça a l'air de rien, mais j'ai déjà commencé à galérer à cette étape.
La doc
indique que la dernière version à jour se trouve
ici.
Perso, je n'ai pas trouvé cette version super fonctionnelle et j'ai opté
pour la version proposée en téléchargement sur le site
officiel.
Étape 2 : configurer l20n avec le manifeste
Le manifeste permet d'indiquer quelles langues sont supportées et quelle
est la langue par défaut.
Le remplissage de ce fichier est assez trivial.
Une fois le manifeste rempli, il faut indiquer où le trouver dans le html.
<script type="application/l10n-data+json">
J'avoue avoir sauté cette étape et utilisé la version proposée dans le
dépot github, dans un premier temps.
Étape 3 : marquer les chaines à traduire
Les chaines à traduire sont identifiées en ajoutant un attribut aux
balises HTML.
Par exemple, si j'ai le texte suivant et que je veux le traduire :
<h1>Bonjour bonjour !</h1>
je le transforme en :
<h1 data-l10n-id="code_hello">Bonjour bonjour !</h1>
Là, si vous enregistrez et retournez sur votre site, il ne plus bonjour
mais "code_hello". C'est normal, don't panic !
Étape 4 : traduire !
En effet, il faut maintenant créer les traductions associées aux
éléments identifiés dans le HTML, à l'aide du fameux format de fichier
trop bien qui gère tout un tas de trucs.
C'est là que vous pouvez retourner sur la documentation de l20n et
trouver votre bonheur !
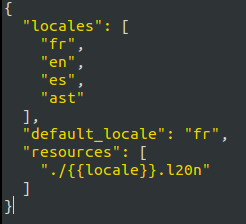
il faut donc créer un fichier pour chaque langue définie dans le
manifeste, à l'endroit défini par le manifeste
locales
├── ast.l20n
├── en.l20n
├── es.l20n
├── fr.l20n
└── manifest.json
Et dans ce fichier, on peut écrire les chaines à utiliser comme
traduction :
Voilà, y a plus qu'à reproduire les étapes 3 et 4 à l'infini !
Bon, ça ne fonctionne pas super bien avec le navigateur
Chromium ... Mais
sous Firefox, c'est impec.
Encore quelques petites remarques :
Comment tester ?
l20n se fonde sur la langue du navigateur pour choisir la langue parmi
celles du manifeste. S'il ne la trouve pas dans son manifeste, il prend
la langue par défaut du manifeste.
Pour changer la langue du navigateur : dans Firefox, c'est dans Outils
> Options ou Édition > Préférences, onglet Contenu.
Il faut bien sûr recharger la page pour que ça prenne effet.
Subtilités (simples) du format génial :
Si vous avez du texte un peu long : il est possible d'avoir la
traduction sur plusieurs lignes
<about_long_contenu """ Voilà un texte très très long !
Tellement long qu'il tient sur plusieurs
lignes """>
Vous remarquerez peut-être qu'il n'est pas possible de mettre des
balises HTML dans le fichier de traduction :(
Pour gérer le cas où on veut traduire tout un paragraphe qui contient
des liens, voici comment procéder
<div data-l10n-id="credits_contenu">
Carte fournie par <a href="http://www.openstreetmap.org" target="_blank">OpenStreetMap</a>
</div>
puis
<credits "Carte fournie par <a>OpenStreetMap</a>">
pas très intuitif, mais tout à fait efficace.
Pour le reste, je vous invite à jeter un oeil à cette
adresse.
19 mai 2014
EDIT : pour suivre l'actualité d'OpenBeerMap, suivez le mot-dièse
#OpenBeerMap et le journal
OSM https://www.openstreetmap.org/user/OpenBeerMapContributor/diary
Parfois, lorsque je sors avec des acolytes, on se retrouve dans un bar
qui sert une bière blonde dégueulasse tout juste bonne à faire
des panachés classique, et on découvre en sortant que le bar d’à côté
sert de la bière belge d’abbaye.
Je ne suis pas une grande amatrice de bière, mais je trouve ça plutôt
frustrant.
Et qui dit frustration dit besoin sous-jacent.
Et qui dit besoin dit « il me faut une application pour ça ! »
Bref, c’est ainsi qu’il m’est venu l’idée de faire une carte affichant
les bars et les bières qui y sont servies, à partir des données
OpenStreetMap bien sûr !
Le résultat est visible ici : http://openbeermap.github.io/
Voici comment ça s’est déroulé.
Bon, j’ai commencé par apprendre les bases du javascript (parce que mon
langage de prédilection, c’est plutôt le python, mais c’est quand même
nettement moins adapté pour faire des cartes sur le web).
Je suis parti d’un plugin Leaflet (qui est un bibliothèque javascript
efficace pour afficher des cartes) pour afficher des données à partir
de l’API
Overpass.
L’API Overpass (qui est testable sur cet IDE
(http://overpass-turbo.eu/) permet de faire des requêtes sur les
données OSM avec toutes sortes de filtres.
Dans mon cas, c’est amenity = pub (ou bar ou cafe) et brewery =
{nom de ma bière}
Assez rapidement et sans y connaitre grand-chose, j’ai pu faire une joli
carte avec des cases à cocher pour les différents types de bière :
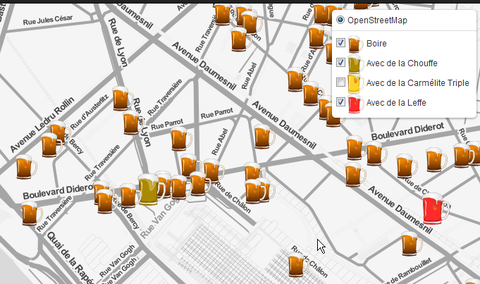
Puis, j’ai intégré tout ça dans
BootLeaf, une template basé sur
Leaflet et Bootstrap, afin d’avoir quelque chose de responsive et
surtout de plus joli, notamment sur mes info-bulles
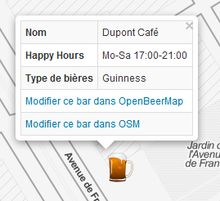
Puis, je me suis rendue compte que j’avais pas beaucoup de bars où
l’information était fournie …
Un petit tour sur
Taginfo m’apprend qu’il
n’y a que 15 objets dans OSM sur toute la France avec le tag brewery de
renseigné !
Autant dire qu’il y a du travail de contribution à prévoir si je veux
que mon site ait vraiment un intérêt.
Du coup, j’en profite pour rajouter un petit formulaire permettant de
renseigner directement sur le site les bières dispo, et les autres infos
pertinentes (pour l’instant, j’ai retenu uniquement nom du bar, accès
wifi, heures d’ouverture et heures d’happy hours) :
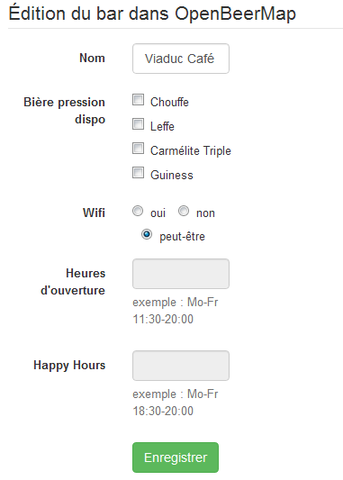
Les informations saisies dans le formulaires partent directement
enrichir la base de données OpenStreetMap, ce qui me permet de les
re-consommer derrière pour afficher quelles bières sont dispo : un
cercle vertueux à consommer sans modération ;)
C'était la partie la plus délicate à réaliser pour moi qui n'était pas
familière avec l'API d'édition d'OSM et toute la cinématique nécessaire
pour réaliser des modifications ... D'ailleurs, la gestion des conflits
a été soigneusement éludée pour le moment...
Bon, j’ai finalement temporairement retiré les heures (opening_hours et
happy_hours) car je pense qu’un simple champ texte n’est pas très
adapté pour enrichir ce type de donnée : j’oublie moi-même tout le temps
le format de ce tag et je n’ai pas très envie d’implémenter une
vérification du format dans le formulaire, donc ce n’est pas optimal …
affaire à suivre.
Maintenant, y a plus qu’à !
Je compte sur vous pour participer et ajouter les bières servies dans
vos débits de boisson favoris.
Et sinon, c’est tout open-source, et toute contribution est la
bienvenue !
Par exemple, si une âme charitable avec des compétences en graphisme
pouvait me fournir des images (en SVG et libre de droit) des verres à
bières, ça serait merveilleux. J’ai essayé de dessiné le verre de la
Kwak … mais j’ai renoncé !
EDIT : c'est chose faite, tout juste 4 mois après le lancement du
projet : Affligem, Carmélite Triple, Chouffe, Guinness et même Kwak ont
leurs icônes intégrées dans OpenBeerMap

Et l'ergonomie pourrait être améliorée sur le choix des bières (aussi
bien sur l'affichage que la contribution) j'imagine.
16 mai 2014
Oui, encore un article sur les lignes de bus dans OSM ! Promis, après
j'arrête. D'ailleurs, je fais faire très court !
Toujours dans l'idée d'enrichir et d'améliorer la qualité des données
OSM à l'aide des données opendata disponibles dans
navitia, voici un quick hack, facile et, si
j'ose dire, à la portée de n'importe qui :p
Prenons, par exemple, la ligne 325 de la RATP : c'est une ligne très
simple, sans fourche ou boucle ou autres joyeusetés.
Dans OSM, elle est plutôt pas mal cartographiée, on a l'essentiel des
routes et une grande partie des arrêts.
Mais, en utilisant sketch-line (l'outil de génération de thermomètre de
ligne à partir des données
OSM), le résultat est
... décevant ...
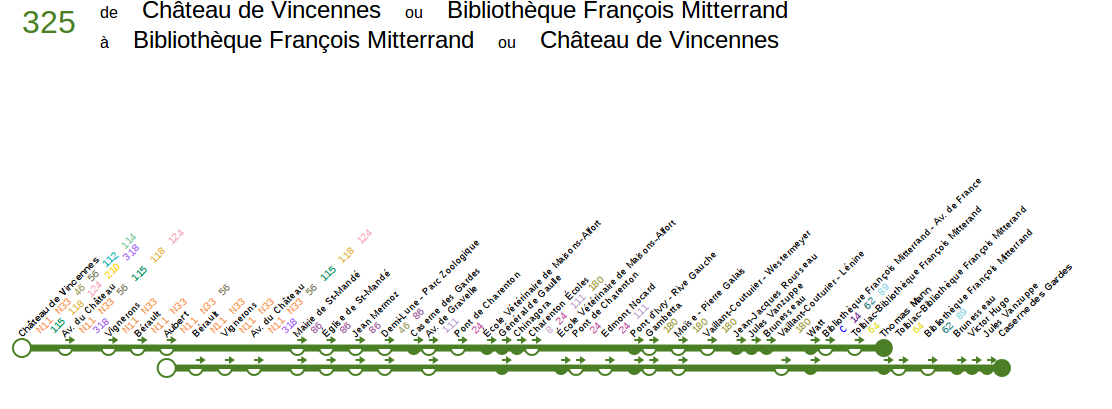
source
: http://overpass-api.de/api/sketch-line?network=RATP&ref=325&style=paris%C2%A0
Déjà, OSM n'arrive même pas clairement à déterminer son origine et sa
destination ... Ensuite, ses parcours ont l'air assez chaotiques.
C'est un cas typique où les arrêts sont mal ordonnés dans les relations
(car oui, les relations sont ordonnées ! relisez la partie théorique de
mon article sur la carto d'une ligne de bus si vous avez un doute).
Comment remédier à tout ça et avoir nettoyer la donnée dans OSM ?
En utilisant navitia.io évidemment :p
Pas de script cette fois-ci, juste un appel pour récupérer l'ordre des
dessertes :

Puis, il suffit de regarder ce qu'il y a dans OSM et de corriger si
nécessaire dans JOSM (car l'éditeur iD ne permet pas de modifier l'ordre
des éléments dans une relation) :
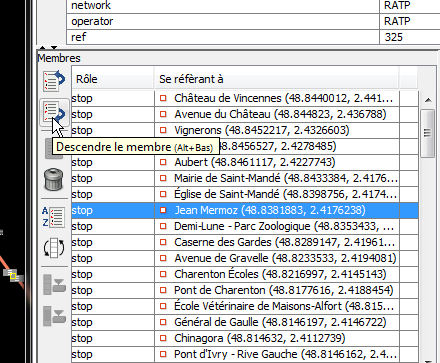
On peut aussi en profiter pour corriger les fautes dans les noms
(Brunesseau ou Bruneseau ? École vétérinaire de Maisons Alfort ou
Maisons Alfort école vétérinaire ? etc)
C'est un peu long mais pas difficile.
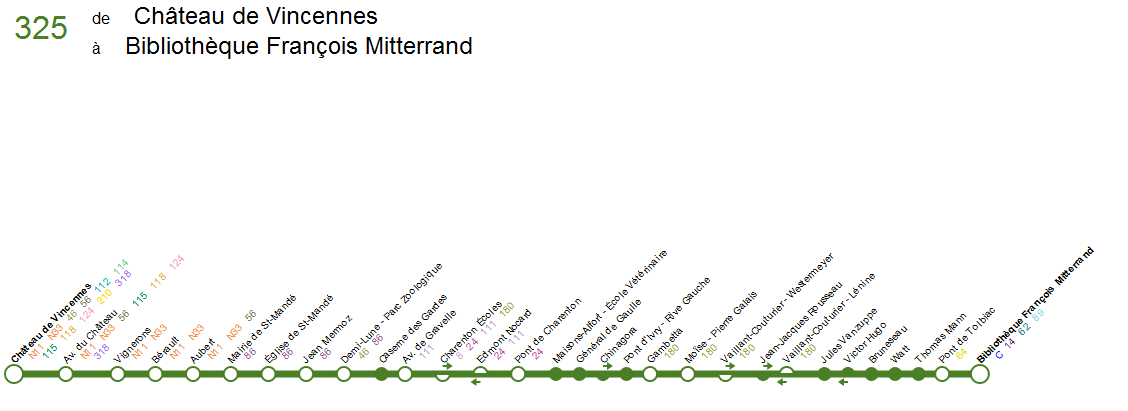
Et assez rapidement, on se retrouve avec un thermomètre de ligne tout
beau tout propre, et surtout qui reflète nettement mieux la réalité !
29 avril 2014
Vous l'aurez compris, mon TOC (trouble obsessionnel cartographique) du
moment, c'est les arrêts de bus !
Et en travaillant sur le projet KartoKartier,
avec mes collègues, dans le cadre du concours
Cartoviz, je me suis rendue compte
qu'il y avait une belle marge de manoeuvre pour améliorer la qualité des
données OSM pour les arrêts de bus : j'en parlais
ici.
C'est ainsi que je me suis mise en tête de faire un script qui se
nourrit de l'opendata RATP via l'API navitia.io,
pour enrichir les données OSM en ajoutant, pour commencer, les noms des
arrêts manquants.
Ce script est disponible sur
github,
et librement réutilisable.
Que fait ce script ?
Tout d’abord, il récupère la liste de tous les arrêts de bus, situé dans
la ville de Paris (par exemple), qui n’ont pas de nom renseigné.
J'ai commencé par l'utiliser sur des villes plus proches de la mienne,
voici quelques métriques :
- nombre d’arrêts sans nom à Paris : 267
- nombre d’arrêts sans nom à Boissy-Saint-Léger : 21
- nombre d’arrêts sans nom à Sucy-en-Brie : 38
- nombre d’arrêts sans nom à Créteil : 25
- nombre d’arrêts sans nom à Bonneuil-sur-Marne : 3
Ensuite, pour chacun de ces arrêts, j’appelle navitia.io (une API pour
les transports en commun, développée par Kisio Digital (anciennement Canal TP),
et qui s'alimente, entre autres, des données opendata RATP) et je lui
demande de me retourner les points d’arrêts à proximité des coordonnées
du point OSM.
Les données opendata de la RATP, qui sont utilisées dans navitia.io ont
une géolocalisation peu précise, donc en faisant varier la distance
d’accroche, on obtient des résultats plus ou moins pertinents :
Métriques sur Paris :
- Nombre d’arrêts OSM ayant un arrêt RATP à moins de 100 mètres : 249
- Nombre d’arrêts OSM ayant un arrêt RATP à moins de 50 mètres : 221
- Nombre d’arrêts OSM ayant un arrêt RATP à moins de 20 mètres : 145
- Nombre d’arrêts OSM ayant un arrêt RATP à moins de 10 mètres : 74
- Sur ces arrêts, j’ai choisi, dans un premier temps, de ne conserver que
- ceux qui ont un unique arrêt RATP (ou plusieurs arrêts avec le même nom)
- ce sont les plus faciles à intégrer.
Pour ceux-là, je crée un fichier JOSM avec le nom pré-rempli.
Il n’y a plus alors qu’à ouvrir le fichier dans JOSM, à charger les
données existantes autour du point, à vérifier que les infos sont
cohérentes, puis à envoyer la modification dans OSM.
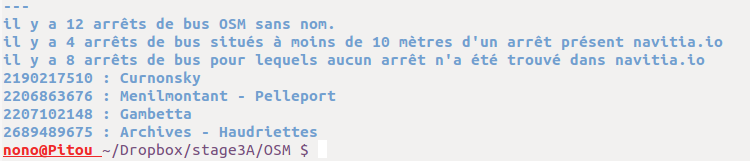
exemple de retour du script

Ci-dessus, le retour du script sur Boissy-St-Léger : il n'y a un seul
arrêt RATP (l'arrêt noctilien que j'ai cartographié dans un article précédent), et il a déjà un
nom !
Dans la pratique, l’intégration :
J’ai choisi d’y aller itérativement, et de commencer par les moins
ambigus, donc ceux ayant un arrêt RATP très proche. J'ai aussi choisi de
commencer par ceux proches de chez moi, pour pouvoir faire une
vérification sur le terrain en cas de doute.
Les premiers arrêts que j'ai intégrés étaient parfaits : c'est le cas
typique
- où navitia a trouvé une correspondance entre mon arrêt sans nom et
les données opendata
- où il n'y a que deux arrêts de bus dans tout le quartier, placé
chacun d'un côté de la route (le sens aller et le sens retour)
- le second arrêt a déjà un nom, et c'est le même que celui trouvé par
navitia
- éventuellement, mon arrêt a un tag name:RATP rempli, et concordant
(mais il a peut-être été aussi généré par un script, je ne sais pas
si c'est vraiment une mesure de fiabilité)
Là, on peut intégrer les yeux fermés :)
Malheureusement, c'est loin de représenter la majorité des cas ...
À vrai dire, j'ai même trouvé une bonne poignée d'exemples carrément
invalides (c'est le cas de le dire) : par exemple, cet arrêt
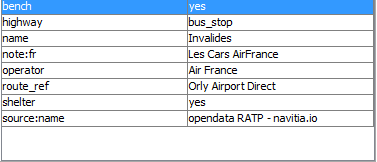
Il est situé à 16 mètres d’un arrêt de bus que l’opendata RATP appelle
Invalides.
Mais, dans les données déjà présentes sur OSM, il est indiqué que c’est
un arrêt desservi par les cars Air France.
En conséquence, navitia, alimenté par des données opendata RATP et SNCF
(et pas Air France) n’est pas une source fiable pour me fournir le nom
de l’arret.
Ça ne veut pas dire que l'arrêt ne s'appelle pas Invalides, mais à moins
d'aller voir sur place, je ne peux pas en être certaine ...
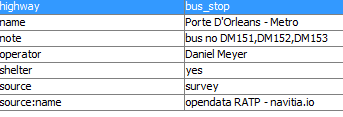
On l'oublie souvent, mais il n'y a pas que la RATP comme opérateur de
transport, même à Paris !
J’ai même découvert des opérateurs de transport que je ne connaissais
pas :
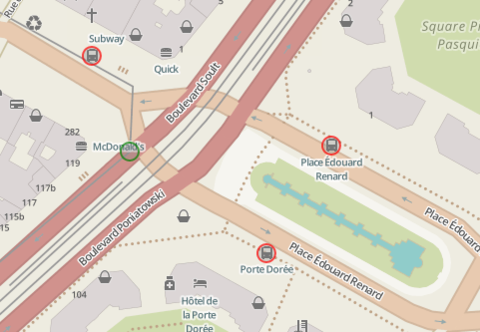
Enfin, il ya aussi des exceptions géographiques étranges : je pense par
exemple aux arrêts de bus autour de Porte Dorée : on trouve deux arrêts,
chacun d'un côté de la route, et il y en a un des deux qui ne s'appelle
pas Porte Dorée !
Bref, on aurait pu croire qu’on pouvait tout importer automatiquement,
mais en creusant un peu, on se rend compte que souvent, il y a des
petites subtilités et qu’une vérification humaine est effectivement
nécessaire. On comprend ainsi beaucoup mieux les réticences de la
communauté OSM face aux imports massif de données d’autres sources
(c'est d'ailleurs pour ça qu'on parle ici d'intégration, et non
d'import).
État des lieux :
En bref ... aujourd'hui, j'ai intégré tous les arrêts RATP des villes
proches de chez moi (Boissy, Sucy, Bonneil, Créteil). Mais
malheureusement, ils ne représentent pas la majorité des arrêts de bus
de ces villes, qui sont massivement desservies par d'autres compagnies,
dont les données de transport ne sont pas en opendata, et donc pas dans
navitia.io !
Sur Paris, il m'en reste aujourd'hui moins de 100 !
Et après ?
Les possibilités sont multiples : par exemple, l'intégration dans Osmose
pourrait permettre à d'autres contributeurs de vérifier avant d'envoyer
les modifications dans OSM (comme ce qui est fait pour les données
opendata des écoles par exemple).
Il serait intéressant également de regarder les rejets de mon script,
comme les arrêts OSM ayant plusieurs arrêts opendata (avec un nom
différent) à proximité : sur ceux-là, une vérification sur le terrain
s'impose pour choisir entre les possibilités.
Ensuite, pourquoi pas réfléchir à l'intégration des lignes de bus RATP à
partir de navitia.io !
De plus, OSM est un projet international, et navitia aussi, donc le
modèle pourrait s'exporter sans soucis ...
Mais j'attends surtout l’opendata des données transports sur toute
l’Île-de-France, pour compléter les villes près de chez moi !
EDIT 2015 : c'est fait, les données de toute l'Île-de-France sont librement accessibles
EDIT 2017 : mise à jour de quelques liens cassés
15 avril 2014
Bon, maintenant qu’on a indiqué les lignes qui s’arrêtaient à la gare de
Boissy (ici, puis
là), pourquoi ne pas aller
plus loin et cartographier carrément les lignes entières ?!
Je me suis livrée à cette expérience sur les lignes que j’emprunte
occasionnellement, notamment la ligne J1, du transporteur STRAV, puis
des portions des lignes 12 et 23 de l’opérateur SETRA.
Avant-après, ligne J1
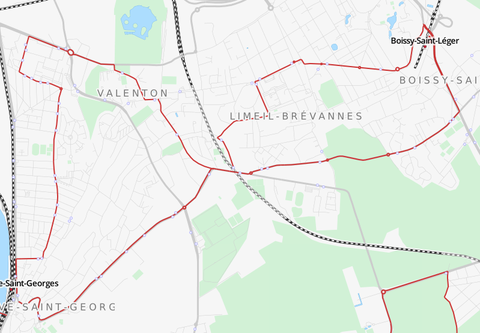
Première étape : le terrain
La première étape est similaire à précédemment, ça consiste à monter
dans le bus et à enregistrer une trace GPS.
La partie difficile à ce niveau est de bien noter les bus_stop (et
éventuellement leurs caractéristiques : banc, abri), en particulier si
l’arrêt n’est pas demandé par les voyageurs qui sont dans le bus …
De retour sur son PC, on peut attaquer la saisie :
Deuxième étape : la création des relations
Avant de créer quoique ce soit, il faut vérifier si ça n’existe pas
déjà !
Par une petite recherche dans le
wiki
tout d'abord
Par une petite recherche dans les données OSM :
Dans overpass-turbo, je demande toutes les
relations, qui ont comme tag network = SITUS (par exemple)
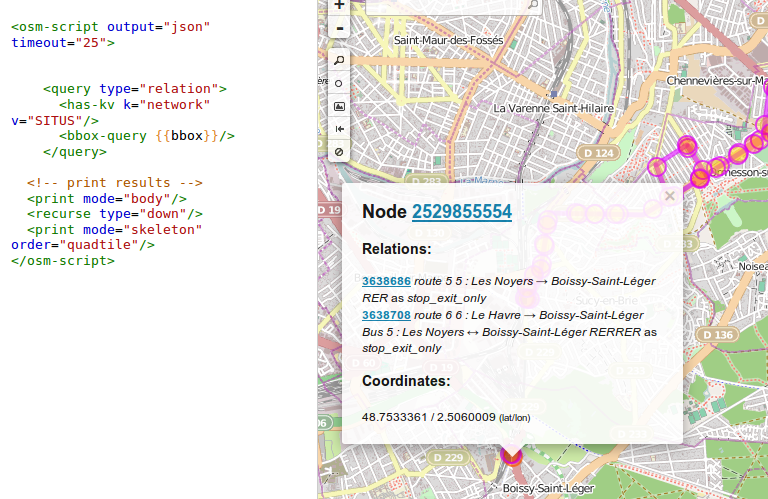
En l’occurrence, je les ai déjà créés précédemment donc on peut sauter
cette étape ;)
Mais j’ai été étonnée de trouver des lignes du réseau SITUS déjà
cartographiée !
Troisième étape : la saisie des arrêts et l’ajout à la relation
Je commence par saisir les arrêts. Certains existent déjà, d’autres non.
Puis comme précédemment, je les ajoute à mes relations.
Là, il y a des petites choses amusantes : parfois il y a déjà un arrêt
qui existe, mais pas exactement au même endroit : comment savoir si
c’est le même déjà existant (et dans ce cas, s’il est bien positionné)
ou s’il y en a plusieurs assez proches ? Dans ce cas, un second passage
sur le terrain s’impose !
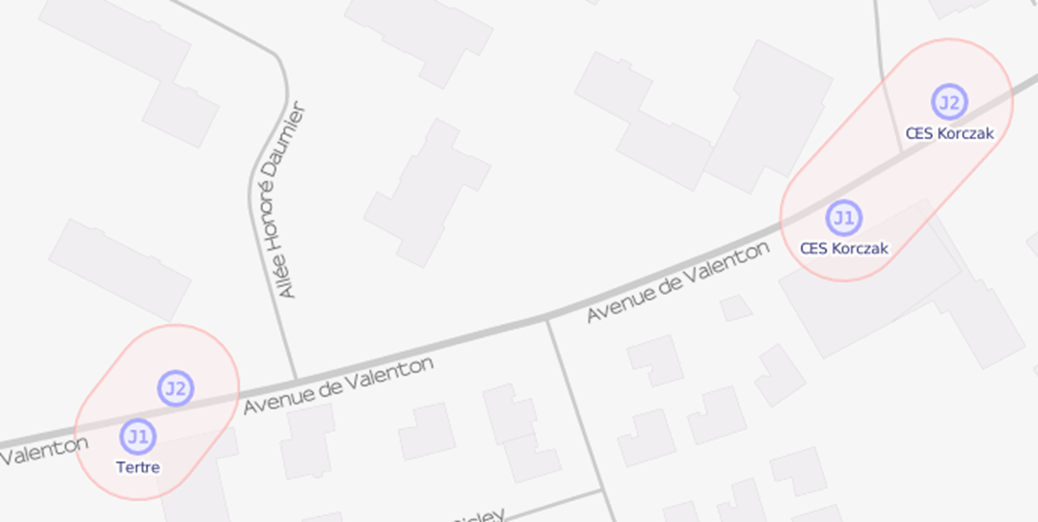
Certains arrêts ont déjà un tag local_ref = J1, ce qui donne le rendu
suivant sur OSM avec la couche de calque Transports :
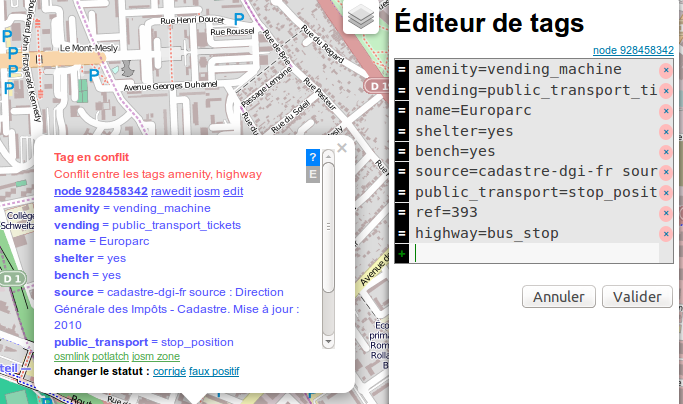
Sur la ligne 23, j’ai également rencontré la problématique suivante :
Les arrêts de bus n’étaient pas marqués comme des arrêts de bus mais
comme des terminaux permettant d’acheter des ticketsamenity =
vending_machine (ce qui est effectivement le cas, ce sont des arrêts
de bus à haut niveau de service :p).
J’ai voulu ajouter juste le tag précisant que c’est un arrêt de bus
(highway = bus_stop).
Mais Osmose (un outil de détection
d'erreurs et d'incohérences dans les données OSM), remonte ceci comme
une erreur :
J’ai donc fait dû faire deux points très proches, l’un portant la vente
de ticket et l’autre l’arrêt de bus.
À part ces quelques cas particuliers très locaux, c’est une manipulation
assez rébarbative, mais assez simple.
Quoique la ligne J1 m’a donné un peu de fil à retordre, car elle est un
peu spéciale :
- C’est une ligne circulaire (Villeneuve-Saint-Georges vers
Villeneuve-Saint-Georges en passant par Boissy-Saint-Léger)
- Et en forme de 8 (un arrêt est desservi plusieurs fois !)
- Avec un unique sens (le sens retour existe, mais c’est en fait la
ligne J2)
- Mais avec quand même des parcours spéciaux, car il y a des arrêts
scolaires qui ne sont desservis qu’une à deux fois par jour !
Si j’avais su, j’aurais commencé par une plus « normale » !
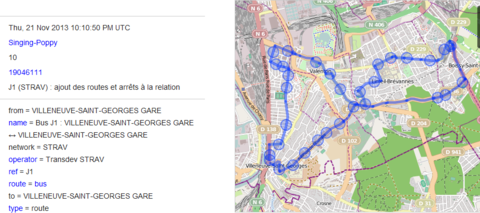
Ça m’a au moins permis de résoudre un mystère : habituellement, je ne le
prenais que pour quelques arrêts, mais effectivement, je m’étais souvent
étonnée du fait que la girouette du bus indiquait parfois
Boissy-Saint-Léger, et parfois Villeneuve Saint-Georges, mais que les
annonces sonores dans le bus disaient toujours « Ligne J1 en direction
de gare de Villeneuve Saint-Georges »…
Quatrième étape : l’ajout des routes dans la relation
Ceci fait, il ne reste plus qu’à ajouter les routes empruntées par le
bus dans les relations.
Là, il n’y a qu’une petite subtilité (qu’on ne peut apprécier qu’au
moment de l’étape 5) :
Dans le cas où le bus tourne avant la fin de la route telle qu’elle est
tracée sur OSM, ça donne des choses inexactes et plutôt moches en terme
de rendu :
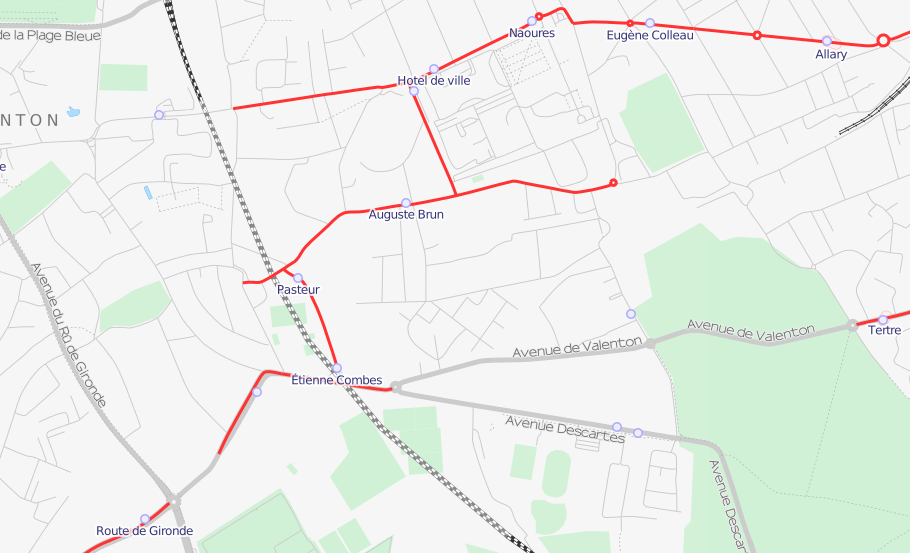
La solution est ici de couper le chemin (là, j’avoue, je n’ai pas trouvé
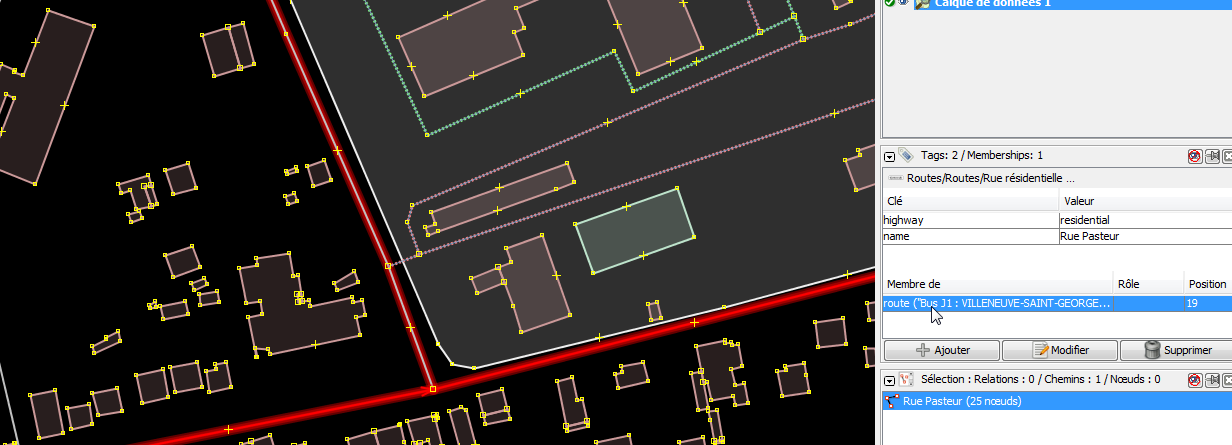
toute seule, j’ai demandé un peu d’aide à la communauté OSM) :
Dans JOSM, quand je survole la relation, les éléments se mettent en
surbrillance :
Ensuite, il suffit de cliquer à l’endroit où on veut tronçonner le
chemin, donc sur le point de séparation, puis de taper P (ou
sélectionner Données > Couper le chemin)
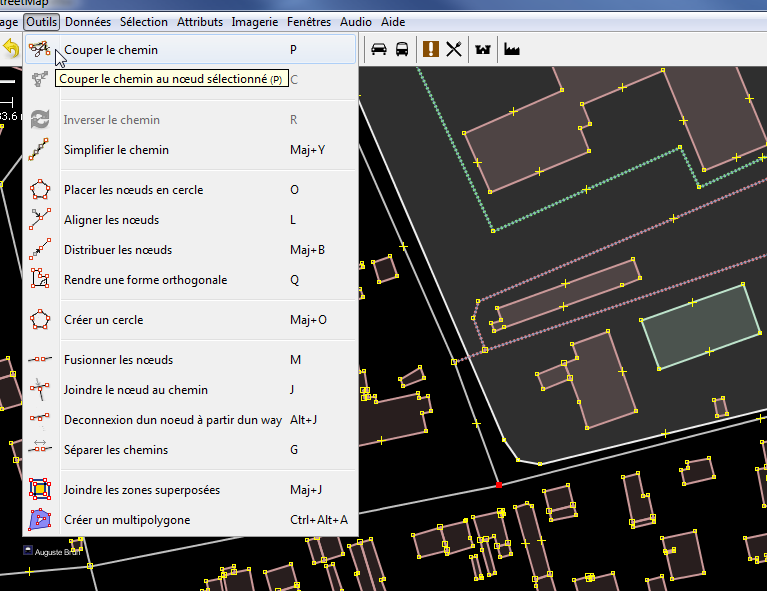
J’ai maintenant deux chemins (sur la capture, j’en ai sélectionné juste
un, ce qui n’était pas possible avant) :
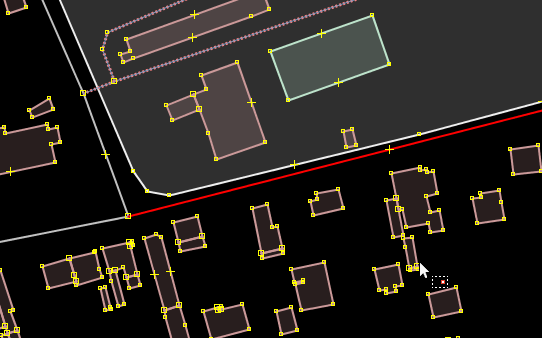
Puis, il ne reste plus qu’à modifier la relation pour supprimer le bout
de chemin qui ne devrait pas y être :
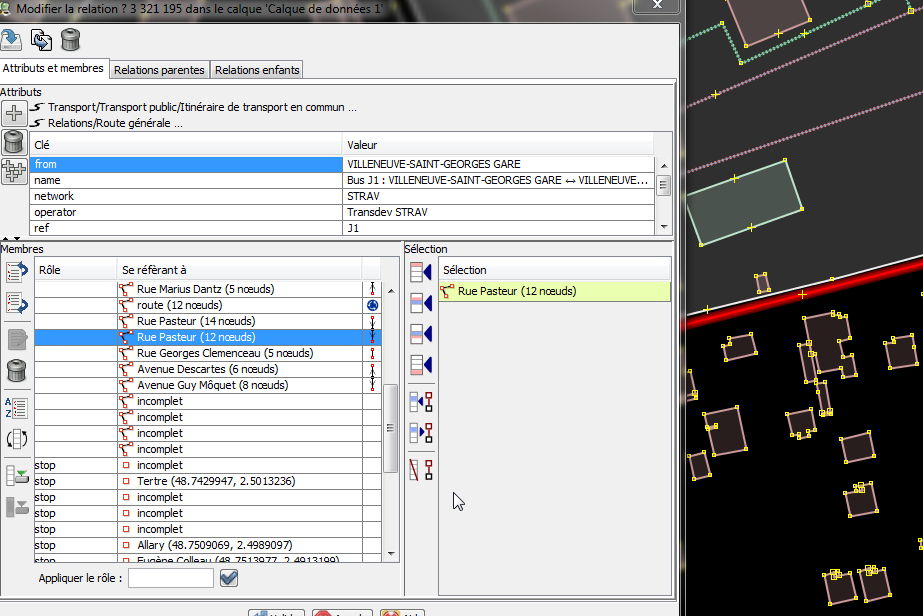
Vous remarquerez au passage dans JOSM que le fait de cliquer sur un
membre le met en surbrillance sur la carte, ce qui permet de ne pas
supprimer le mauvais ;)
Ne pas oublier d’enregistrer, sinon, il faudra le refaire trois fois …
Voilà le résultat final :
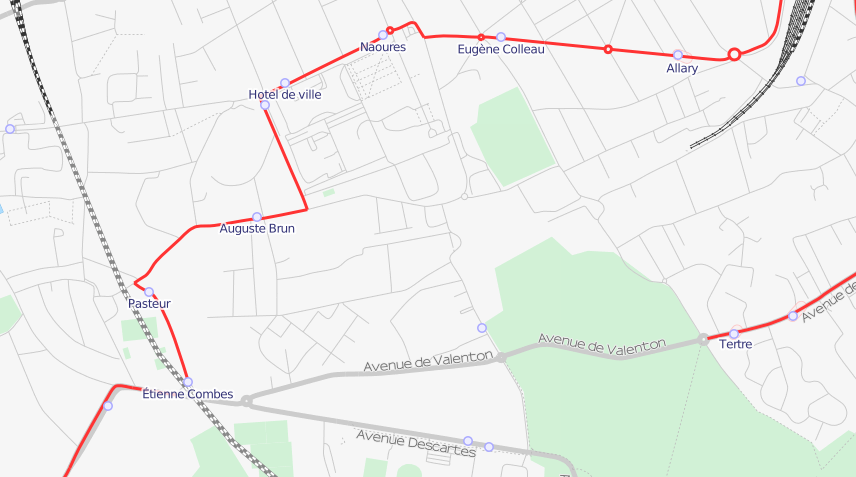
Cinquième étape : ~~admirer~~ vérifier son travail !
Sur le wiki, les liens du modèle (que j'ai déjà évoqué dans le premier
article) peuvent être utiles
pour vérifier son travail :
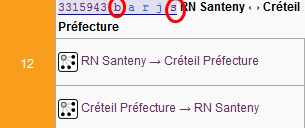
La première vérification, la plus immédiate, est l’affichage de la
relation dans OSM (c’est le premier lien du modèle inséré dans le
wiki) :
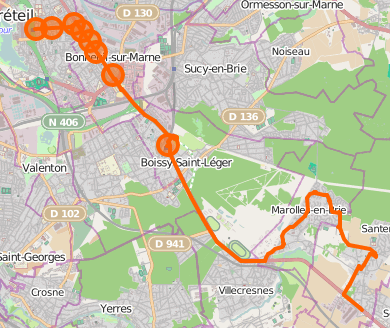
Exemple avec la ligne 12 (je n’ai cartographié que la moitié, le reste
était déjà présent)
Le dernier lien du modèle est également très intéressant, il
reconstruit, à partir des données OSM, le thermomètre de la ligne :
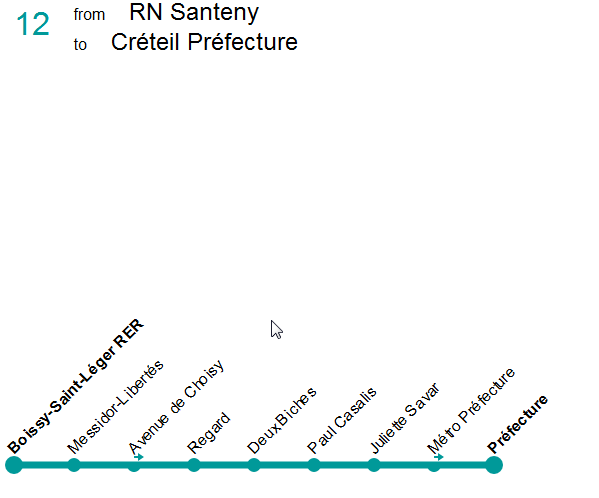
Exemple sur la ligne 12
Et enfin, il y a le rendu de la couche
transport, mais c’est moins
immédiat, car il est mis à jour sur une base régulière plus espacée.
Voilà pour ce petit retour d’expérience sur la cartographie d’une ligne
de bus, qui j’espère suscitera des vocations ;)